Shared Repository: #
Once a database appears, it is unlikely to go away. I see the following evolutions to improve performance of the data layer:
- Shard the database.
- Use Space-Based Architecture for dynamic scalability.
- Divide the data into a private database per service.
- Deploy specialized databases (Polyglot Persistence).
Shard the database #
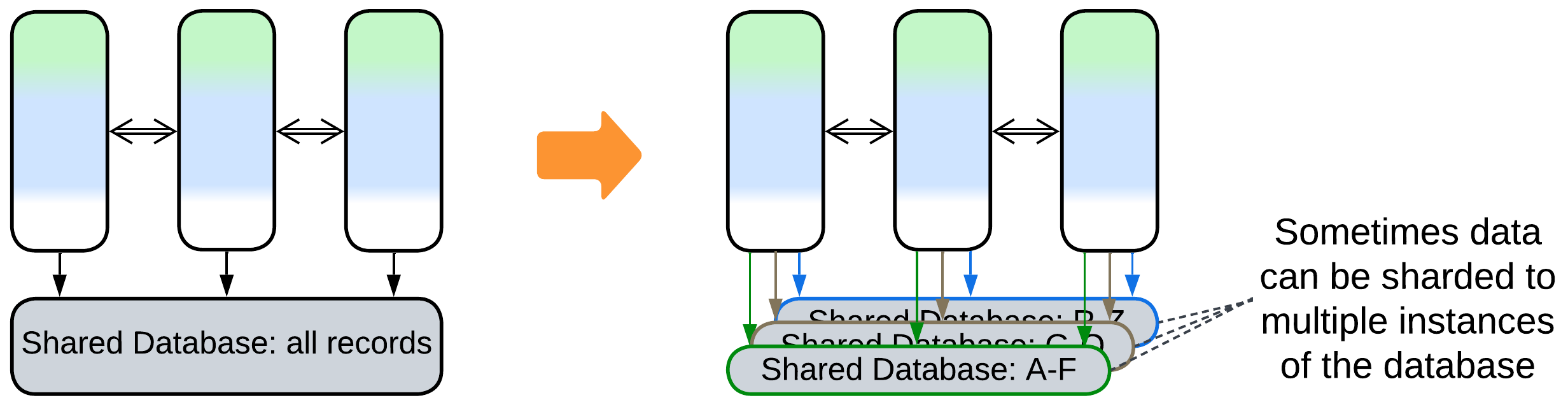
Patterns: Sharding (Shards), Shared Repository, maybe Sharding Proxy.
Goal: increase capacity and performance of the database.
Prerequisite: the data is shardable (consists of independent records).
If your database is overloaded and the data which it contains describes independent entities (users, companies, sales) you can deploy multiple instances of the database with subsets of the data distributed among them. You will need to deploy a Sharding Proxy or the services will have to find out which database shard to access by themselves, likely through hashing the record’s primary key [DDIA]. There is also a good chance that several smaller tables will have to be replicated to all the shards or moved to a dedicated Shared Database (resulting in Polyglot Persistence).
Modern distributed databases support sharding out of the box, but an overgrown table may still impact the performance of the database.
Pros:
- Unlimited scalability.
- You don’t need to change your database vendor.
- Failure of a single database instance affects few users.
Cons:
- You need to manage many instances of the database.
- The application or a custom script may have to synchronize shared tables among the instances.
- There is no way to do joins or run aggregate functions (such as sum or count) over multiple shards – all that logic moves to the services that use the database.
Further steps:
- Polyglot Persistence or CQRS describe pre-calculating aggregates into another analytical database (Reporting Database).
- Space-Based Architecture may be cheaper as it scales dynamically. However, in its default and highly performant configuration it is prone to write collisions.
Use Space-Based Architecture #
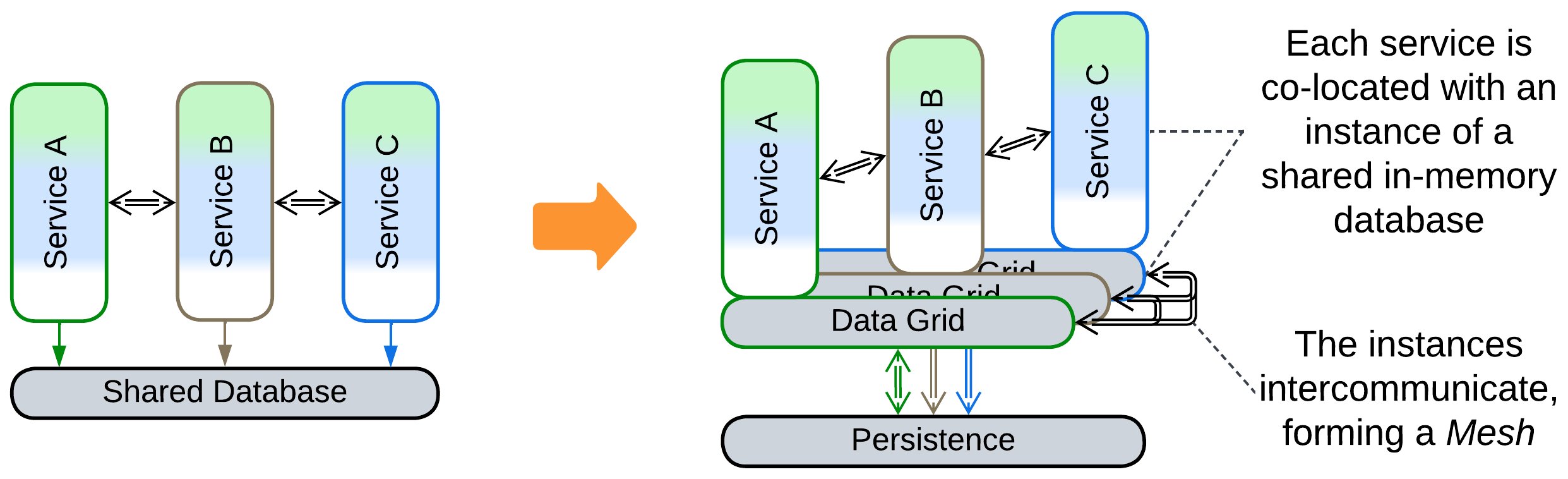
Patterns: Space-Based Architecture (Mesh, Shared Repository).
Goal: scale throughput of the database dynamically.
Prerequisite: data collisions are acceptable.
Space-Based Architecture (SBA) duplicates contents of a persistent database to a distributed in-memory cache co-located with the services managed by the SBA’s Middleware. That makes most database access operations very fast unless one needs to avoid write collisions. The Mesh Middleware autoscales both the services and the associated data cache under load, granting nearly perfect scalability. However, this architecture is costly because of the amount of traffic and CPU time spent on replicating data between the Mesh nodes.
Pros:
- Nearly unlimited dynamic scalability.
- Off-the-shelf solutions are available.
- Very high fault tolerance.
Cons:
- Choose one: data collisions or poor performance.
- Low latency is guaranteed only when the entire dataset fits in the memory of a node.
- High operational cost because the nodes will send each other lots of data.
- No support for analytical queries.
Move the data to private databases of services #
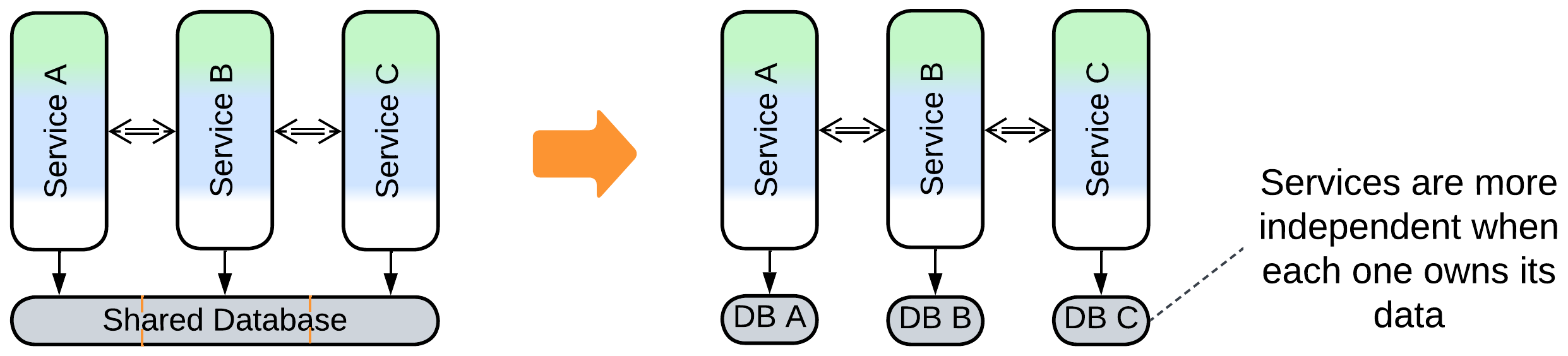
Patterns: Services or Shards, Layers.
Goal: decouple the services or shards, remove the performance bottleneck (Shared Database).
Prerequisite: the domain data is weakly coupled.
If the data clearly follows subdomains, it may be possible to subdivide it accordingly. The services will become choreographed (or orchestrated if they have an integration layer) instead of communicating through the shared data.
Pros:
- The services become independent in their persistence and data processing technologies.
- Performance of the data layer, which tends to limit the scalability of the system, will likely improve thanks to the use of smaller specialized databases.
Cons:
- The communication between the services and the synchronization of their data becomes a major issue.
- Joins of the data from different subdomains will not be available.
- Costs are likely to increase because of data transfer and duplication between the services.
- You will have to administrate multiple databases.
Further steps:
- CQRS Views [MP] or a Query Service [MP] help a service access and join data that belongs to other services.
Deploy specialized databases #
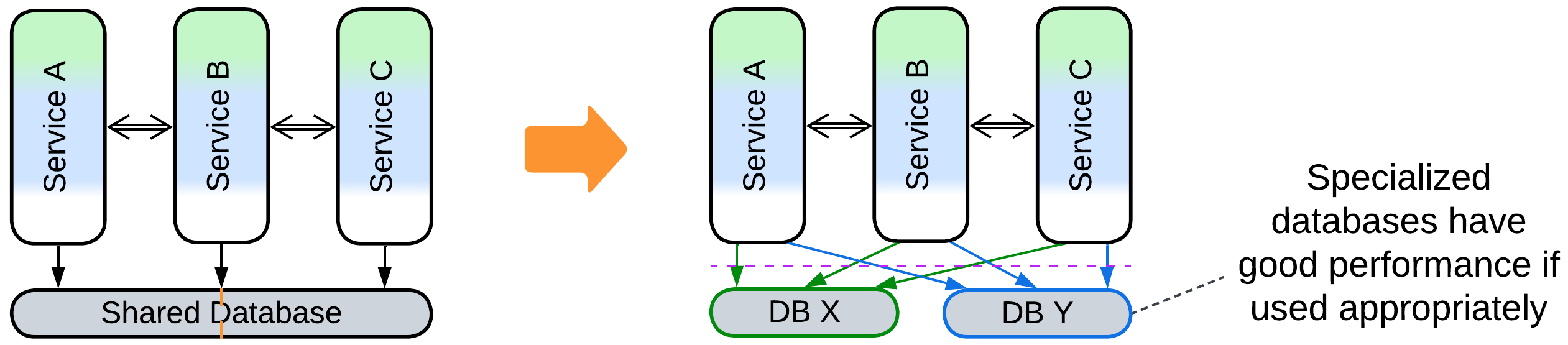
Patterns: Polyglot Persistence.
Goal: improve performance and maybe fault tolerance of the data layer.
Prerequisite: there are diverse data types or patterns of data access.
It is very likely that you can either use specialized databases for various data types or deploy read-only replicas of your data for analytics.
Pros:
- You can choose one of the many specialized databases available on the market.
- There is a good chance to significantly improve performance.
- Replication improves fault tolerance of your data layer.
Cons:
- It may take effort to learn the new technologies and use them efficiently.
- Someone needs to see to the new database(s).
- You’ll likely need to work around replication lag [MP].