Shards: share data #
One issue peculiar to Shards is that of coordinating the instances deployed, especially if their data become coupled. The most direct solution is to let the instances operate a component that wraps the shared data:
- If the whole dataset needs to be shared, it can be split into a Shared Repository layer.
- If data collisions are tolerated, Space-Based Architecture promises low latency and dynamic scalability.
- If a part of the system’s data becomes coupled, only that part can be moved to a Shared Repository, causing each instance to manage two data stores: private and shared.
- Another option is to split out a service to own the coupled data and always deploy it as a single instance. The remaining parts of the system become coupled to that service, not each other.
Move all the data to a Shared Repository #
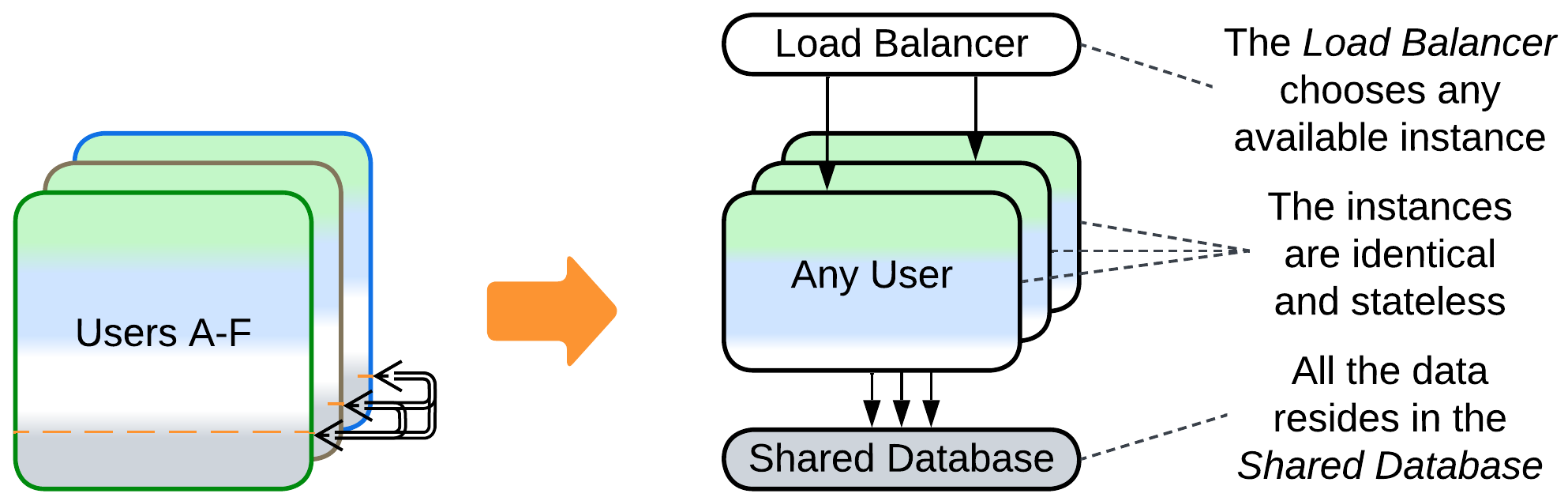
Patterns: Pool (Shards), Shared Database (Shared Repository), Load Balancer (Proxy), Layers.
Goal: don’t struggle against the coupling of the shards, keep it simple and stupid.
Prerequisite: the system is not under pressure for data size or latency (which can be addressed by the further evolutions).
In case a shard needs to access data owned by any other shard, the prerequisite of the independence of shards starts to fall apart. Grab all the data of all the shards and push it into a Shared Database, if you can (there may be too much data or the database access may be too slow). As all the shards become identical, you’ll likely add a Load Balancer.
Pros:
- You can choose one of the many specialized databases available.
- The stateless instances of the main application become dynamically scalable.
- Failure of a single instance affects few users.
- Canary Release is supported.
Cons:
- The database limits the system’s scalability and performance.
- The Load Balancer and Shared Database increase latency and are single points of failure.
Further steps:
- Hexagonal Architecture will let you change your database in the future.
- Space-Based Architecture decreases latency by co-locating subsets of the data and your application.
- Polyglot Persistence uses multiple specialized databases, often by separating commands and queries. That may greatly relieve the primary (write) database.
- CQRS goes even further by processing read and write requests with dedicated services.
Use Space-Based Architecture #
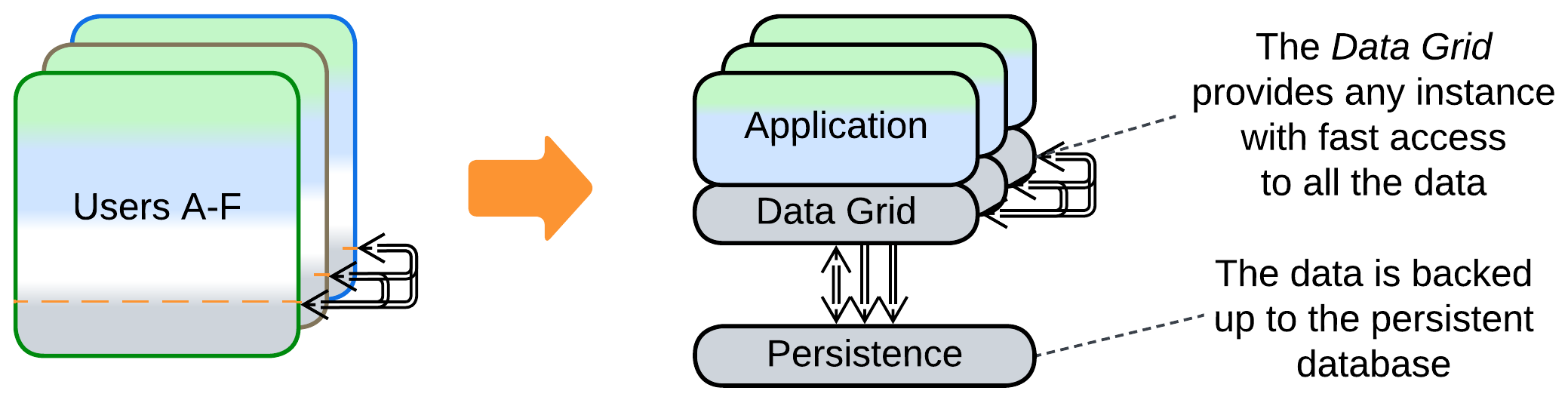
Patterns: Space-Based Architecture (Mesh, Shared Repository), Shards, Layers.
Goal: don’t struggle against the coupling between the shards, maintain high performance.
Prerequisite: data collisions are acceptable.
Space-Based Architecture is a Mesh of nodes which consist of the application and a cached subset of the system’s data. A node broadcasts any changes to its data to other nodes and it may request any data that it needs from the other nodes. Collectively, the nodes of the Mesh keep the whole data cached in memory.
Though Space-Based Architecture may provide multiple modes of action, including single write / multiple read replicas, it is most efficient when there is no write synchronization between its nodes, meaning that data consistency is sacrificed for performance and scalability.
Pros:
- Unlimited dynamic scalability.
- Off-the-shelf solutions are available.
- Failure of a single instance affects few users.
Cons:
- Choose one: data collisions or mediocre performance.
- Low latency is supported only for datasets that fit in memory of a single node.
- High operational cost because the nodes exchange huge amounts of data.
- No support for analytical queries.
Use a Shared Repository for a coupled subset of the data #
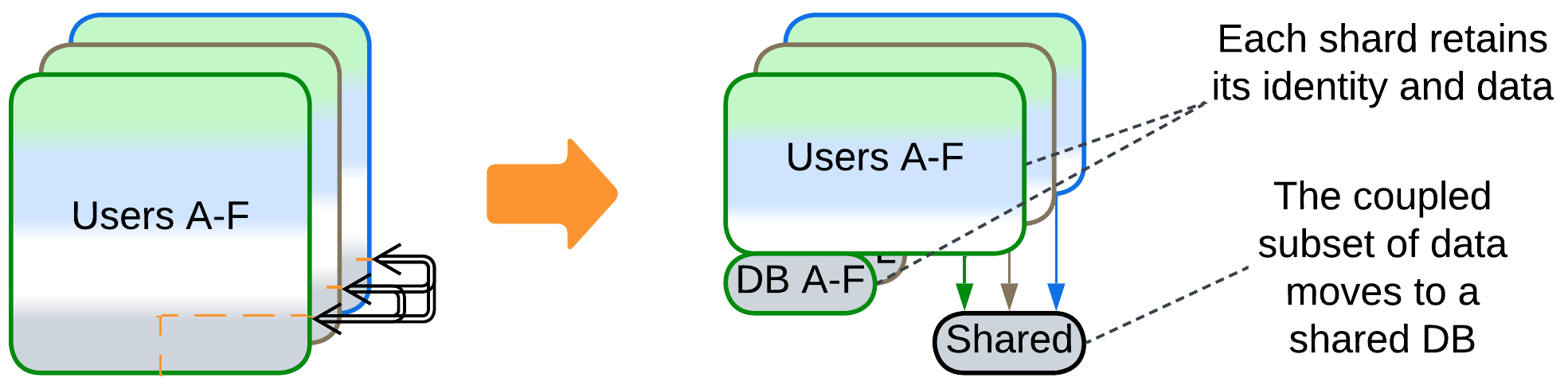
Patterns: Shards, Private and Shared Databases (Polyglot Persistence), Shared Database (Shared Repository), Layers.
Goal: solve the coupling between shards without losing performance.
Prerequisite: the shards are coupled through a small subset of data.
If a subset of the data is accessed by all the shards, that subset can be moved to a dedicated database, which is likely to be fast if only because it is small. Using a distributed database that keeps its data synchronized on all the shards may be even faster.
This approach resembles Shared Kernel [DDD].
Pros:
- You can choose one of the many specialized databases available.
Cons:
- The Shared Database increases latency and is the single point of failure.
Split a service with the coupled data #
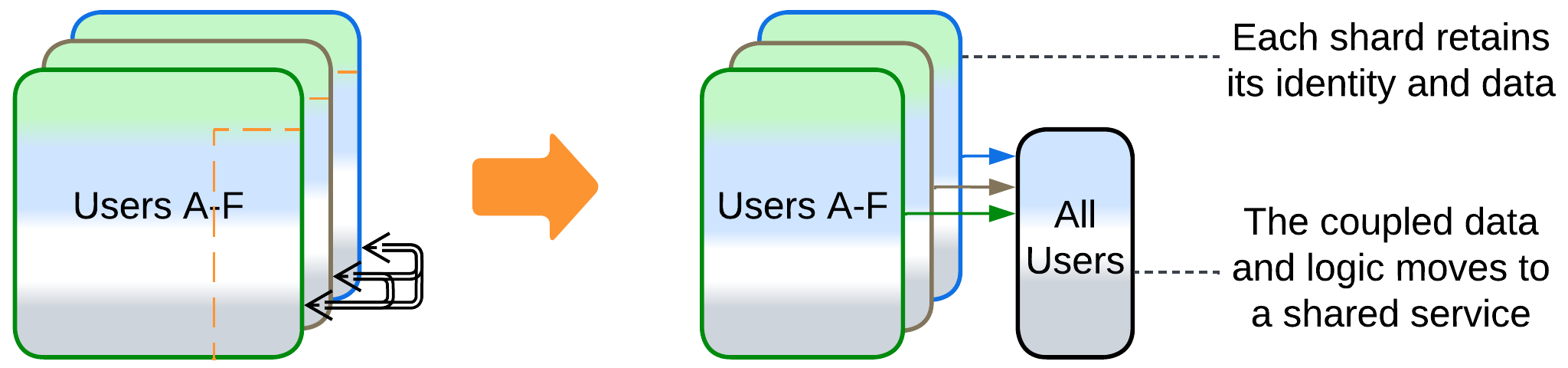
Goal: solve the coupling between the shards in an honorable way.
Prerequisite: the part of the domain which causes coupling between the shards is weakly coupled to the remaining domain.
If a part of the domain is too cohesive to be sharded, we can often move it from the main application into a dedicated service. That way the main application remains sharded while the new service exists as a single instance. In rare cases there is a chance to re-shard the new service with a sharding key which is different from the one used for sharding the main application.
This approach resembles Shared Kernel [DDD].
Pros:
- The main code should become a little bit simpler.
- The new service can be given to a new team.
- The new service may choose a database that best fits its needs.
Cons:
- Now it’s hard to share data between the new service and the main application.
- Scenarios that use the new service are harder to debug.
- There is a moderate performance penalty for using the extra service.