Pipeline: #
Pipeline inherits its set of evolutions from Services. Components can be added, split in two, merged or replaced. Many systems employ a Middleware (pub/sub or pipeline framework), Shared Repository (which may be a database or file system) or Proxies.
There are a couple of Pipeline-specific evolutions:
- The first service of the Pipeline can be promoted to Front Controller [SAHP] which tracks status updates for every request it handles.
- Adding an Orchestrator turns a Pipeline into Services. As the high-level business logic moves to the orchestration layer, the services don’t need to interact directly, the interservice communication channels disappear and the system becomes identical to Orchestrated Services.
Promote a service to Front Controller #
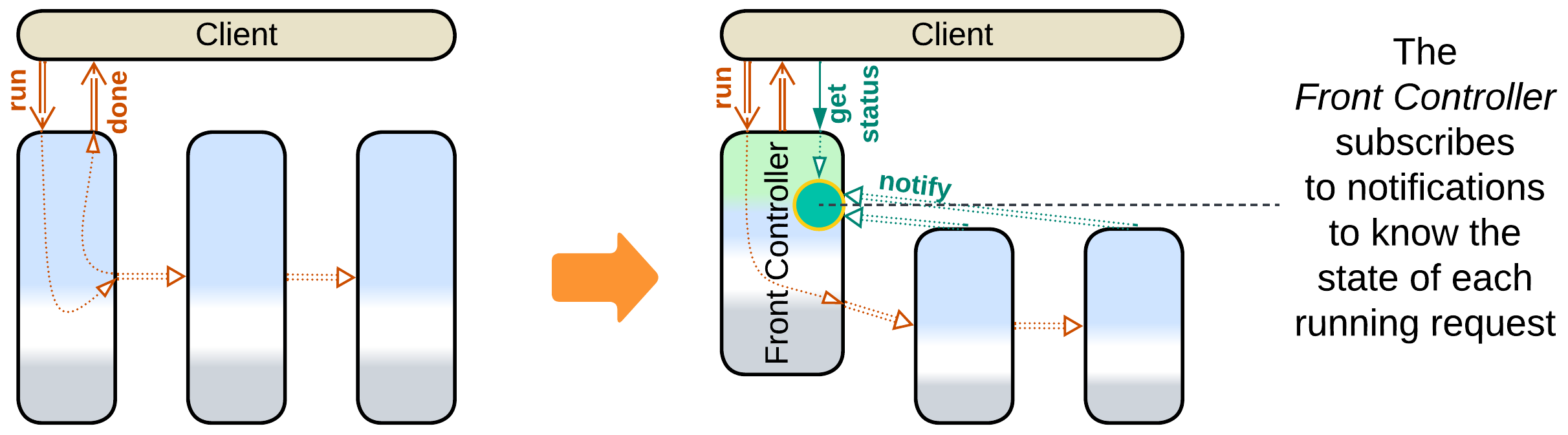
Patterns: Front Controller (Polyglot Persistence, Orchestrator), Pipeline (Services).
Goal: allow for clients to query the state of their requests.
Prerequisite: request processing steps are slow (may depend on human action).
If request processing steps require heavy calculations or manual action, clients may want to query the status of their requests and analysts may want to see bottlenecks in the Pipeline. Let the first service in the Pipeline track the state of all the running requests by subscribing to status notifications from other services.
Pros:
- The state of each running request is readily available.
Cons:
- The first service in the pipeline depends on every other service.
Further steps:
- The Front Controller may be further promoted to Orchestrator if there is a need to support many complex scenarios.
Add an Orchestrator #
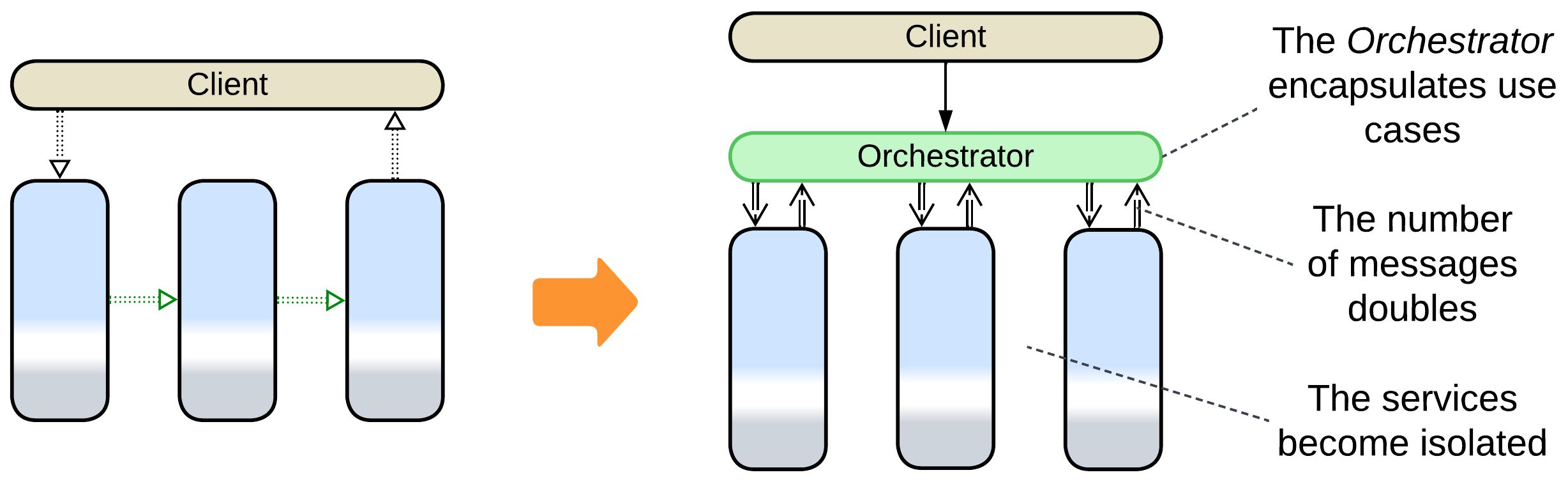
Patterns: Orchestrator, Services.
Goal: support many use cases.
Prerequisite: performance degradation is acceptable.
When a choreographed system is extended with more and more use cases, it is very likely to fall into integration hell where nobody understands how its components interrelate. Extract the workflow logic into a dedicated service.
Pros:
- New use cases are easy to add.
- Complex scenarios are supported.
- The services don’t depend on each other.
- There is a single client-facing team, other teams are not under pressure from the business.
- It is easier to run actions in parallel.
- Global scenarios become debuggable.
- The services don’t need to be redeployed when the high-level logic changes.
Cons:
- The number of messages in the system doubles, thus its performance may degrade.
- The Orchestrator may become a development and performance bottleneck or a single point of failure.
Further steps:
- If there are several clients that strongly vary in workflows, you can apply Backends for Frontends with an Orchestrator per client.
- If the Orchestrator grows too large, it can be divided into layers, services or both, the latter option resulting in a Top-Down Hierarchy.
- The Orchestrator can be scaled and can have its own database.