Monolith: to Shards #
One of the main drawbacks of the monolithic architecture is its lack of scalability – a single running instance of your system may not be enough to serve all its clients no matter how many resources you add in. If that is the case, you should consider Shards – multiple instances of a monolith. There are following options:
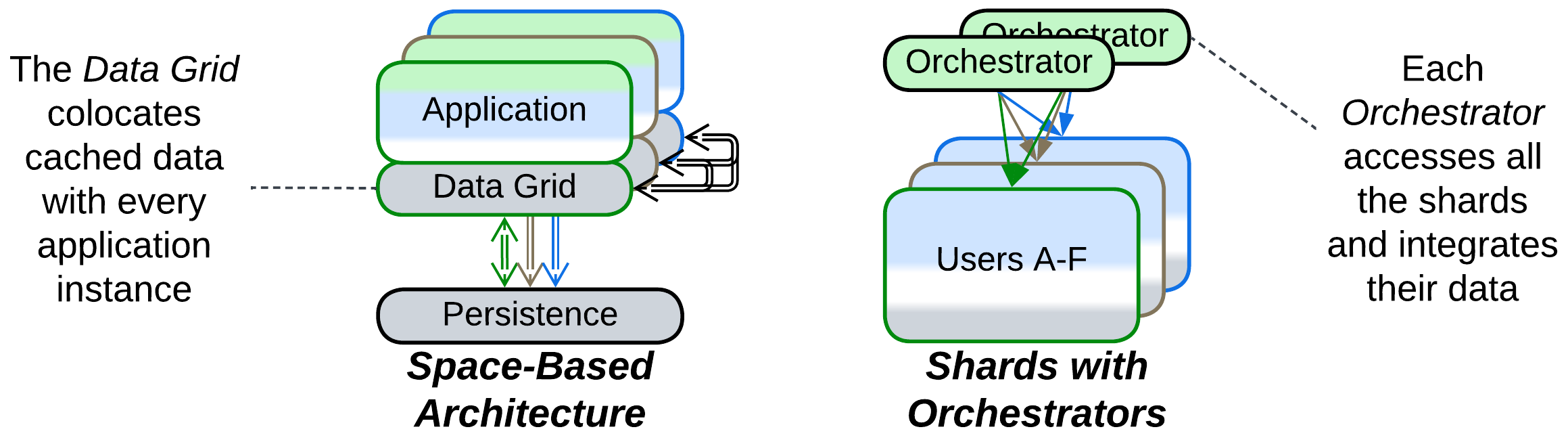
- Self-managed Shards – each instance owns a part of the system’s data and may communicate with all the other instances (forming a Mesh).
- Shards with a Sharding Proxy – each instance owns a part of the system’s data and relies on the external component to choose a shard for a client.
- A Pool of stateless instances with a Load Balancer and a Shared Database – any instance can process any request, but the database limits the throughput.
- A stateful instance per client with an external persistent storage – each instance owns the data related to its client and runs in a virtual environment (i.e. web browser or an actor framework).
Implement a Mesh of self-managed shards #
Patterns: Sharding (Shards), Mesh.
Goal: scale a low-latency application with weakly coupled data.
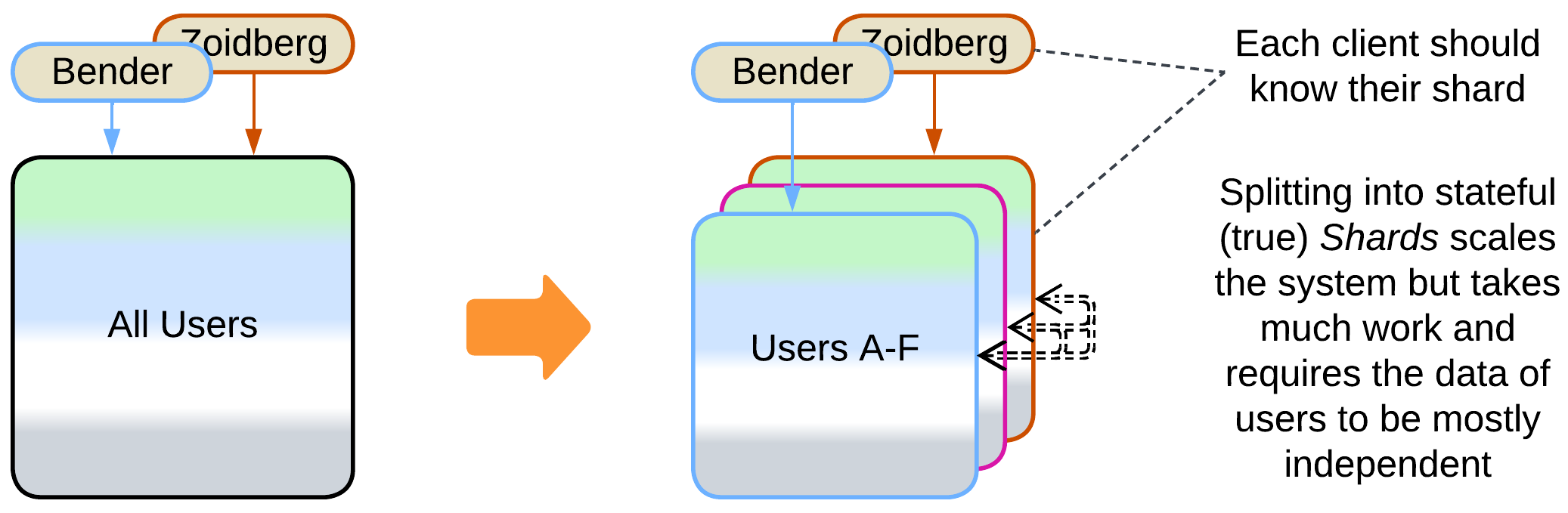
Prerequisite: the application’s data can be split into semi-independent parts.
It is possible to run several instances of an application (shards), with each instance owning a part of the data. For example, a chat may deploy 16 servers , each responsible for a subset of users whose hashed names end in specific 4 bits (0 to 15). However, some scenarios (renaming a user, adding a contact) may require the shards to intercommunicate. And the more coupled the shards become, the more complex a mesh engine is required to support their interactions, up to implementing distributed transactions, at that point you will have written a distributed database.
Pros:
- The system scales to a predefined number of instances.
- Perfect fault tolerance if replication and error recovery are implemented.
- Latency is kept low.
Cons:
- Direct communication between shards (the mesh engine logic) is likely to be quite complex.
- Intershard transactions are slow and/or complicated and may corrupt data if undertested.
- A client must know which shards own its data to benefit from low latency. An Ambassador Sharding Proxy may be used on the client’s side.
Split data to isolated shards and add a Sharding Proxy #
Patterns: Sharding (Shards), Sharding Proxy (Proxy), Layers.
Goal: scale an application with sliceable data.
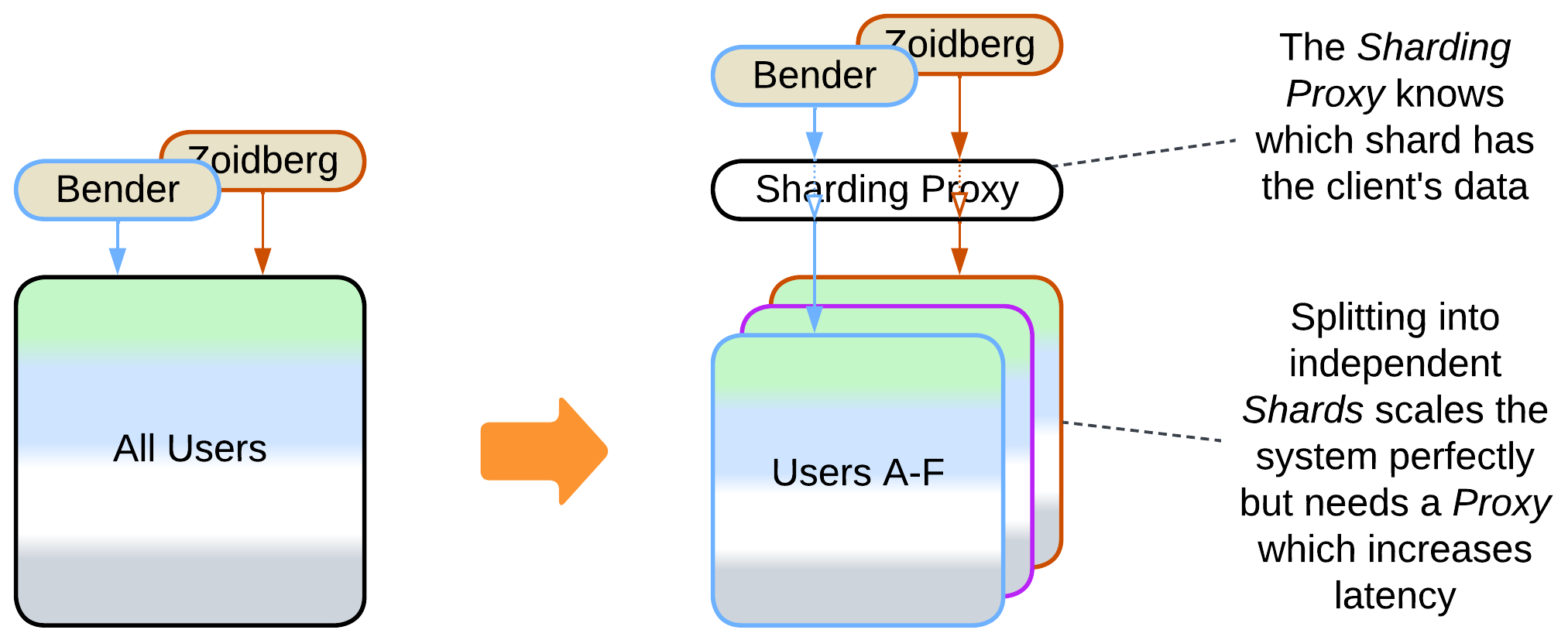
Prerequisite: the application’s data can be sliced into independent, self-sufficient parts.
If all the data a user operates on, directly or indirectly, is never accessed by other users, then multiple independent instances (shards) of the application can be deployed, each owning an instance of a database. A special kind of Proxy, called Sharding Proxy, redirects a user request to a shard that has the user’s data.
Pros:
- Perfect static (predefined number of instances) scalability.
- Failure of a shard does not affect users of other shards.
- Canary Release is supported.
Cons:
- The Sharding Proxy is a single point of failure unless replicated and increases latency unless deployed as an Ambassador [DDS].
Separate the data layer and add a load balancer #
Patterns: Pool (Shards), Shared Database (Shared Repository), Load Balancer (Proxy), Layers.
Goal: achieve scalability with little effort.
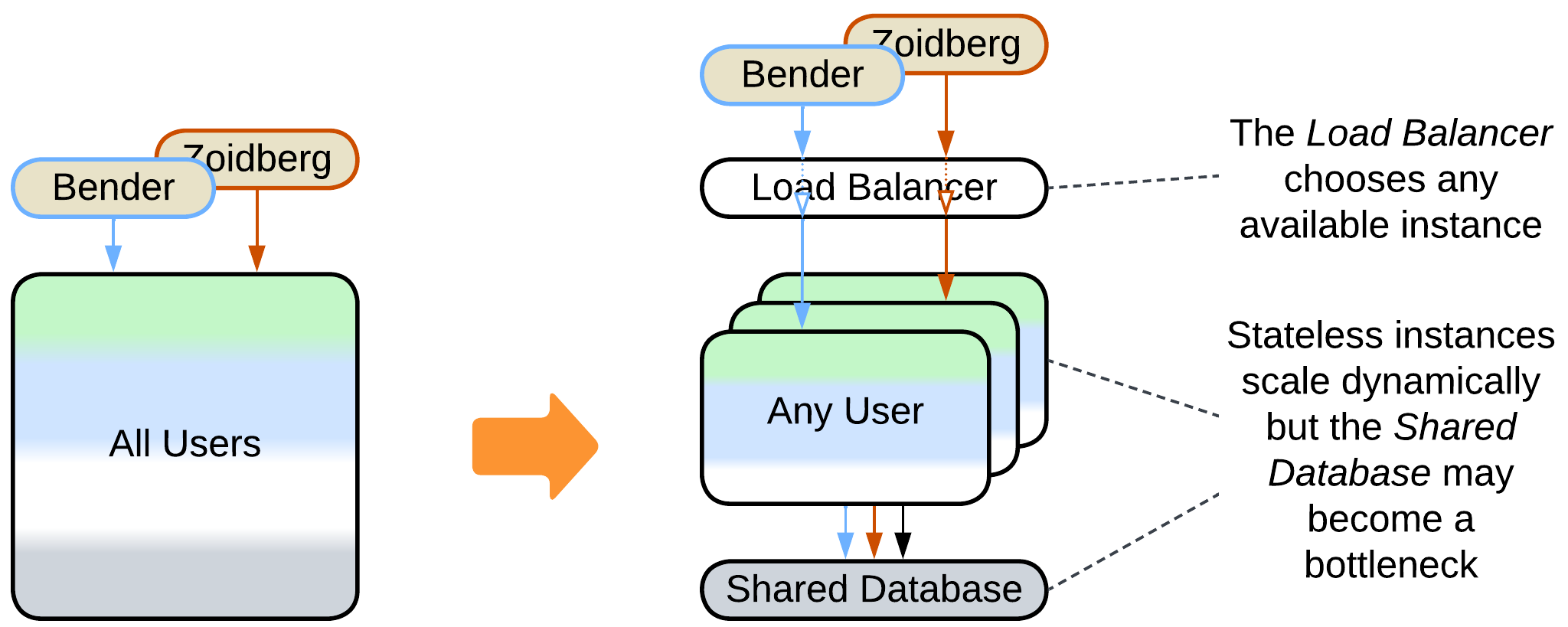
Prerequisite: there is persistent data of manageable size.
As data moves into a dedicated layer, the application becomes stateless and instances of it can be created and destroyed dynamically depending on the load. However, the Shared Database becomes the system’s bottleneck unless Space-Based Architecture is used.
Pros:
- Easy to implement.
- Dynamic scalability.
- Failure of a single instance affects few users.
- Canary Release is supported.
Cons:
- The database limits the system’s scalability and performance.
- The Load Balancer and Shared Database increase latency and are single points of failure.
Dedicate an instance to each client #
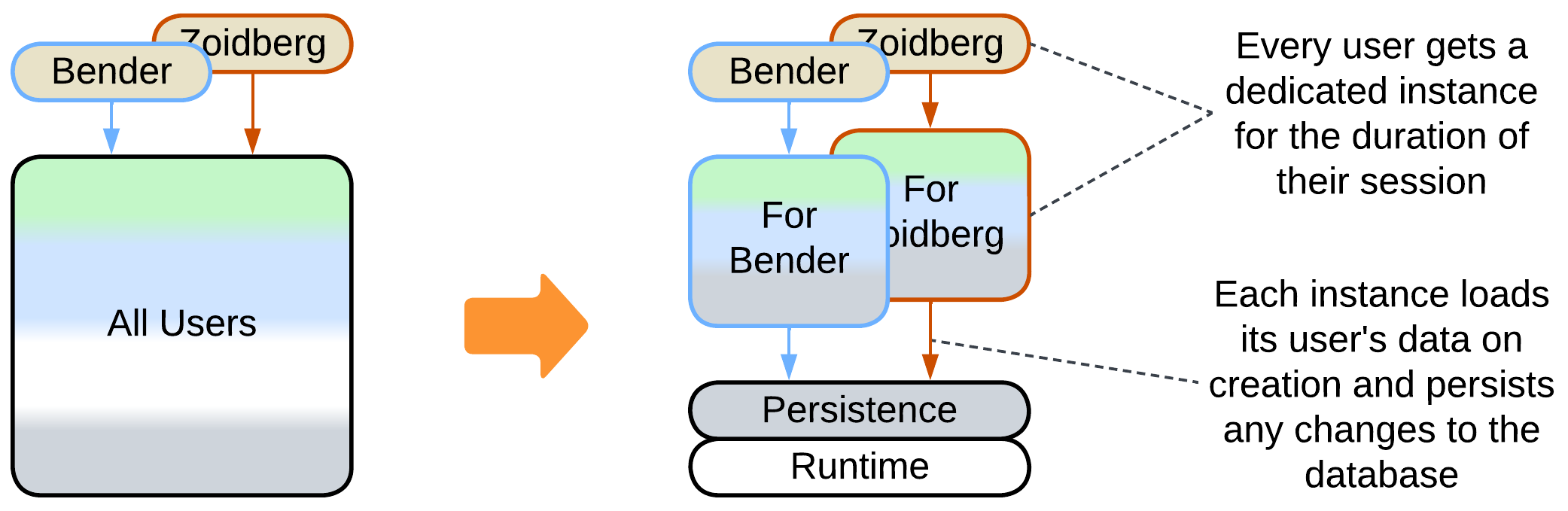
Patterns: Create on Demand (Shards), Shared Repository, Virtualizer (Microkernel), Layers.
Goal: very low latency, dynamic scalability, and failure isolation.
Prerequisite: each client’s data is small and independent of other clients.
Each client gets an instance of the application which preloads their data into memory. This way all the data is instantly accessible and a processing fault from one client never affects the other clients. As systems tend to have thousands to millions of clients, it is inefficient to spawn a process per client. Instead, more lightweight entities are used: a web app in a browser or an actor in a distributed framework.
Pros:
- Nearly perfect dynamic scalability (limited by the persistence layer).
- Good latency as everything happens in RAM.
- Fault isolation is one of the features of distributed frameworks.
- Frameworks are available out of the box.
Cons:
- Virtualization frameworks tend to introduce a performance penalty.
- You may need to learn an uncommon technology.
- Scalability and performance are still limited by the shared persistence layer.
Further steps #
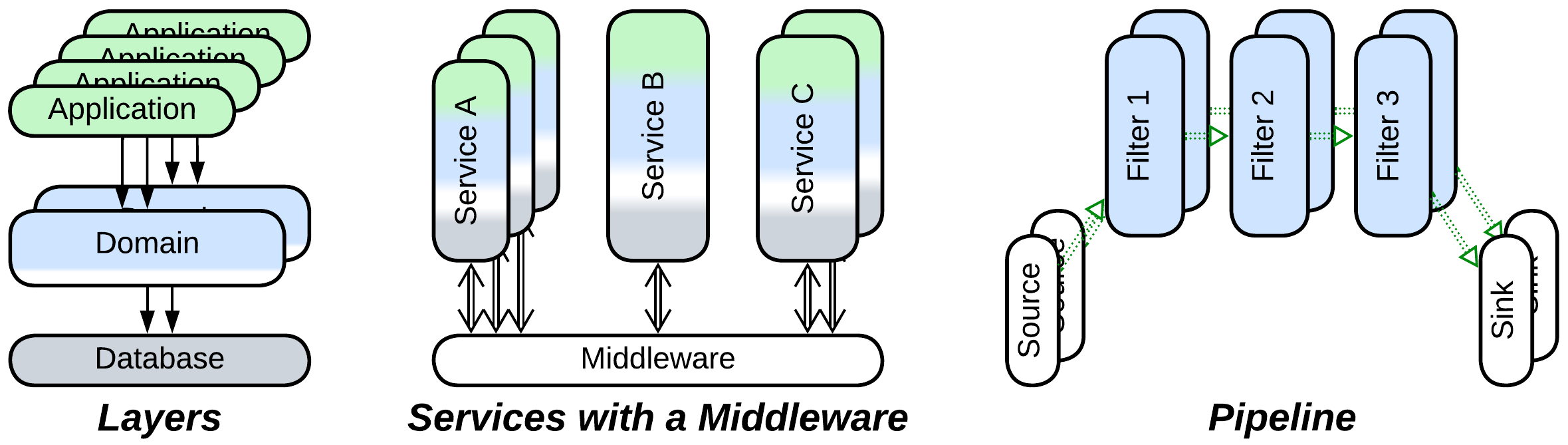
In most cases sharding does not change much inside the application, thus the common evolutions for Monolith (to Layers, Services, and Pipeline) remain applicable after sharding. We’ll focus on their scalability:
- Layers can be scaled (often to a dramatic extent) and deployed individually, as exemplified by the Three-Tier Architecture.
- Services allow for subdomains to scale independently with the help of Load Balancers or a Middleware. They also improve performance of data storage as each service uses its own database which is often chosen to best fit its distinct needs.
- Granular scaling can apply to Pipelines, but in many cases that does not make much sense as pipeline components tend to be lightweight and stateless, making it easy to scale the pipeline as a whole.
There are specific evolutions of Shards that deal with their drawbacks:
- Space-Based Architecture reimplements Shared Repository with Mesh. Its main goal is to make the data layer dynamically scalable, but the exact results are limited by the CAP theorem thus, depending on the mode of action, it can provide very high performance with no consistency guarantees for a small dataset, or reasonable performance for a huge dataset. It blends the best features of stateful Shards and Shared Database (being an option for either to evolve to) but may be quite expensive to run and lacks algorithmic support for analytical queries.
- Orchestrator is a mirror image of Shared Database, another option to implement use cases that deal with data of multiple shards without the need for the shards to intercommunicate. Stateless Orchestrators scale perfectly but may corrupt the data if two of them write to an overlapping set of records.