Layers: improve performance #
There are several ways to improve the performance of a layered system. One we have already discussed for Shards:
- Space-Based Architecture co-locates the database and business logic and scales both dynamically.
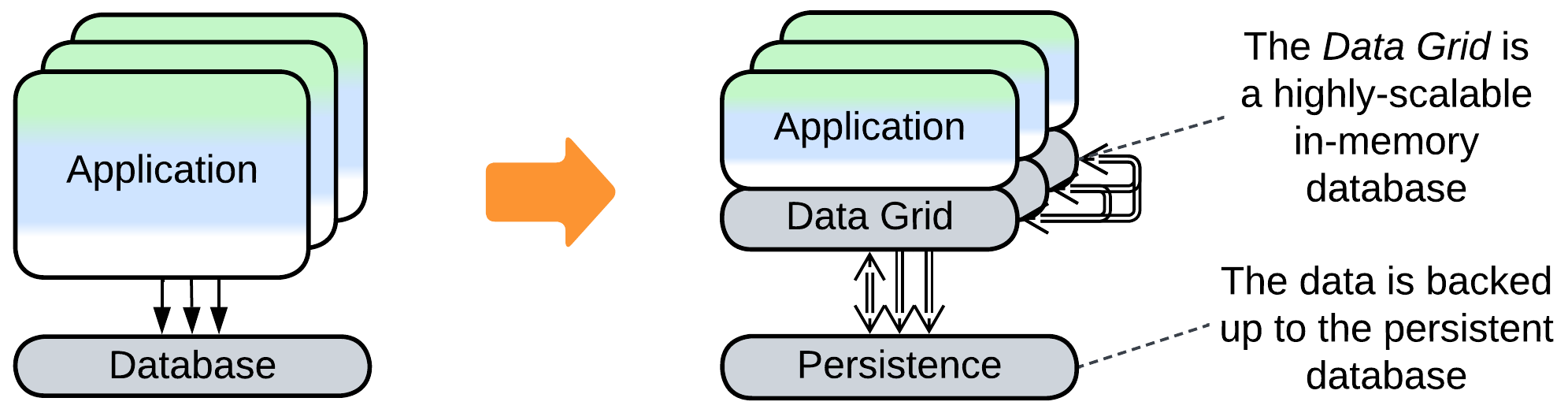
Others are new here and thus deserve more attention:
- Merging several layers improves latency by eliminating the communication overhead.
- Scaling some of the layers may improve throughput but degrade latency.
- Polyglot Persistence is the name for using multiple specialized databases.
Merge several layers #
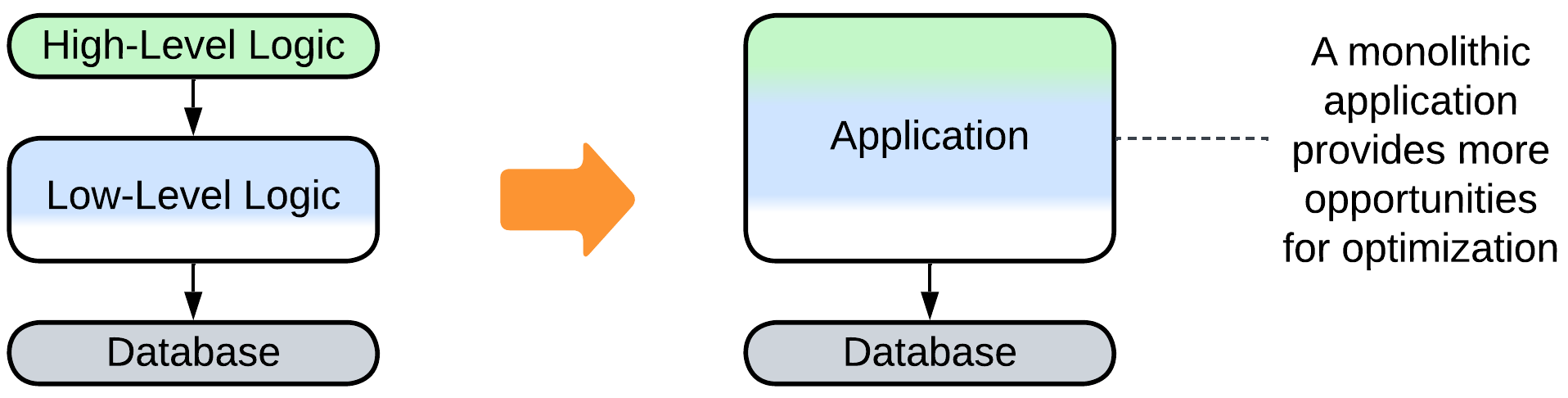
Goal: improve performance.
Prerequisite: the layers share programming language, hardware setup and qualities.
If your system’s development is finished (no changes are expected) and you really need that extra 5% performance improvement, then you can try merging everything back into a Monolith or a 3-Tier system (front, back, data).
Pros:
- Enables aggressive performance optimizations.
- The system may become easier to debug.
Cons:
- The code is frozen – it will be much harder to evolve.
- Your teams lose the ability to work independently.
Further steps:
- Shard the entire system.
Scale individual layers #
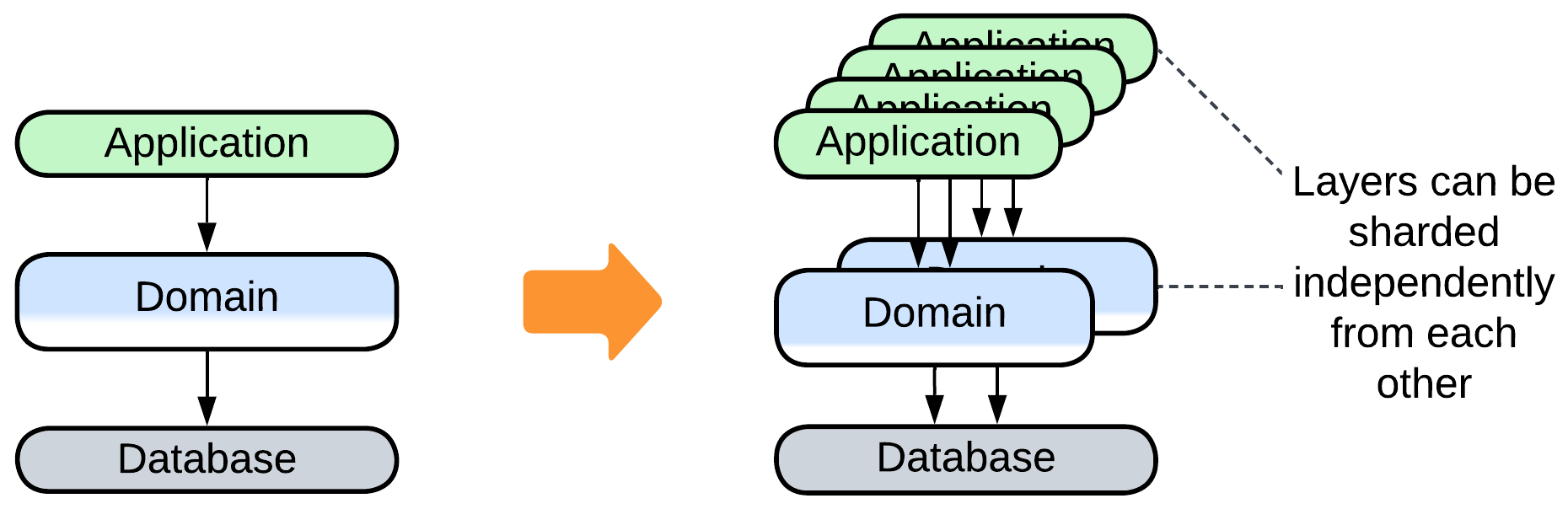
Patterns: Layers, Shards, often Load Balancer (Proxy).
Goal: scale the system.
Prerequisite: some layers are stateless or limited to the data of a single client.
Multiple instances or layers can be created, with their number and deployment varying from layer to layer. That may work seamlessly if each instance of the layer which receives an event which can start a use case knows the instance of the next layer to communicate to. Otherwise you will need a Load Balancer.
Pros:
- Flexible scalability.
- Better fault tolerance.
- Co-deployment with clients is possible.
Cons:
- More complex operations (more parts to keep an eye on).
Further steps:
- Space-Based Architecture scales the data layer.
- Polyglot Persistence improves performance of the data layer.
Use multiple databases #
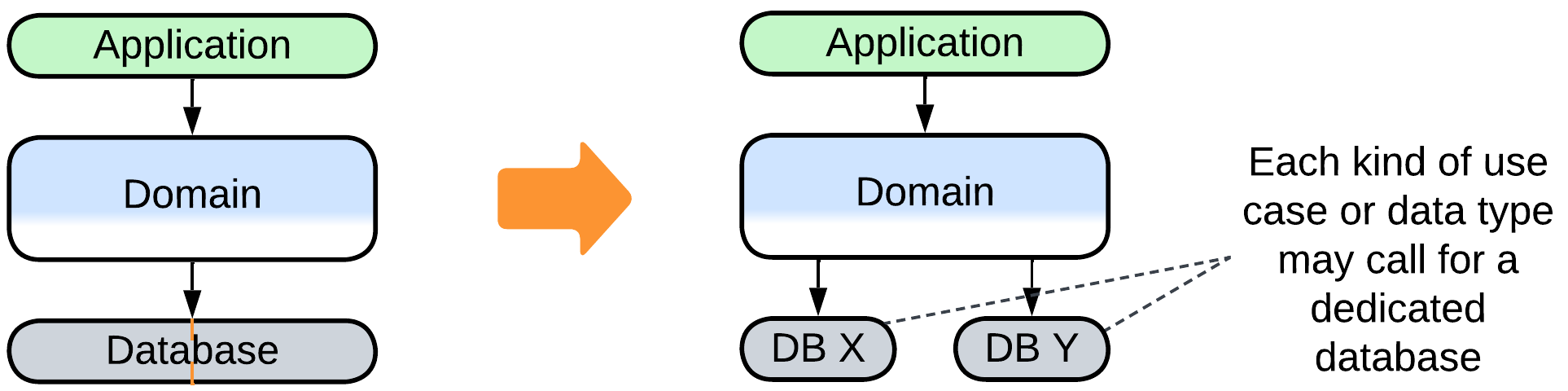
Patterns: Layers, Polyglot Persistence.
Goal: optimize performance of data processing.
Prerequisite: there are isolated use cases for or subsets of the data.
If you have separated commands (write requests) from queries (read requests), you can serve the queries with read-only replicas of the database while the main database is reserved for the commands.
If your types of data or data processing algorithms vary, you may deploy several specialized databases, each matching a subset of your needs. That lets you achieve the best performance in widely diverging cases.
Pros:
- The best performance for all the use cases.
- Specialized data processing algorithms out of the box.
- Replication may help with error recovery.
Cons:
- Someone will need to learn and administer all those databases.
- Keeping the databases consistent takes effort and the replication delay may negatively affect UX.
Further steps:
- Serve read and write requests with different backends according to Command-Query Responsibility Segregation (CQRS).
- Separate the backend into services which match the already separated databases.