Pipelines in architectural patterns #
Several architectural patterns involve a unidirectional data flow – a pipeline. Strictly speaking, every data packet in a pipeline should:
- Move through the system over the same route with no loops.
- Be of the same type, making a data stream.
- Retain its identity on the way.
- Retain temporal order – the sequence of packets remains the same over the entire pipeline.
Staying true to all of these points makes Pipes and Filters – one of the oldest known architectures. Yet there are other architectures that discard one or more of the conditions:
Pipes and Filters #
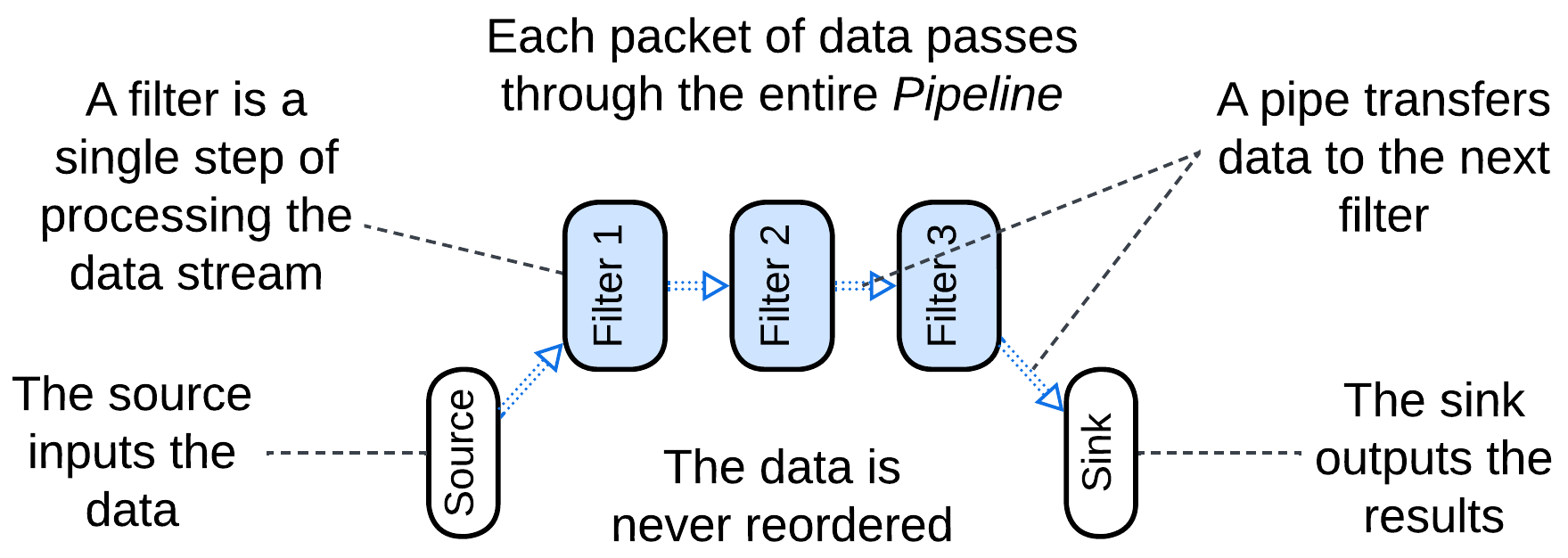
Pipes and Filters [POSA1] is about stepwise processing of a data stream. Each piece of data (a video frame, a line of text or a database record) passes through the entire system.
This architecture is easy to build and has a wide range of applications, from hardware to data analytics. Though each pipeline is specialized for a single use case, a new one can often be built of the same set of generic components – this skill is mastered by Linux admins through their use of shell scripts.
Choreographed Event-Driven Architecture #
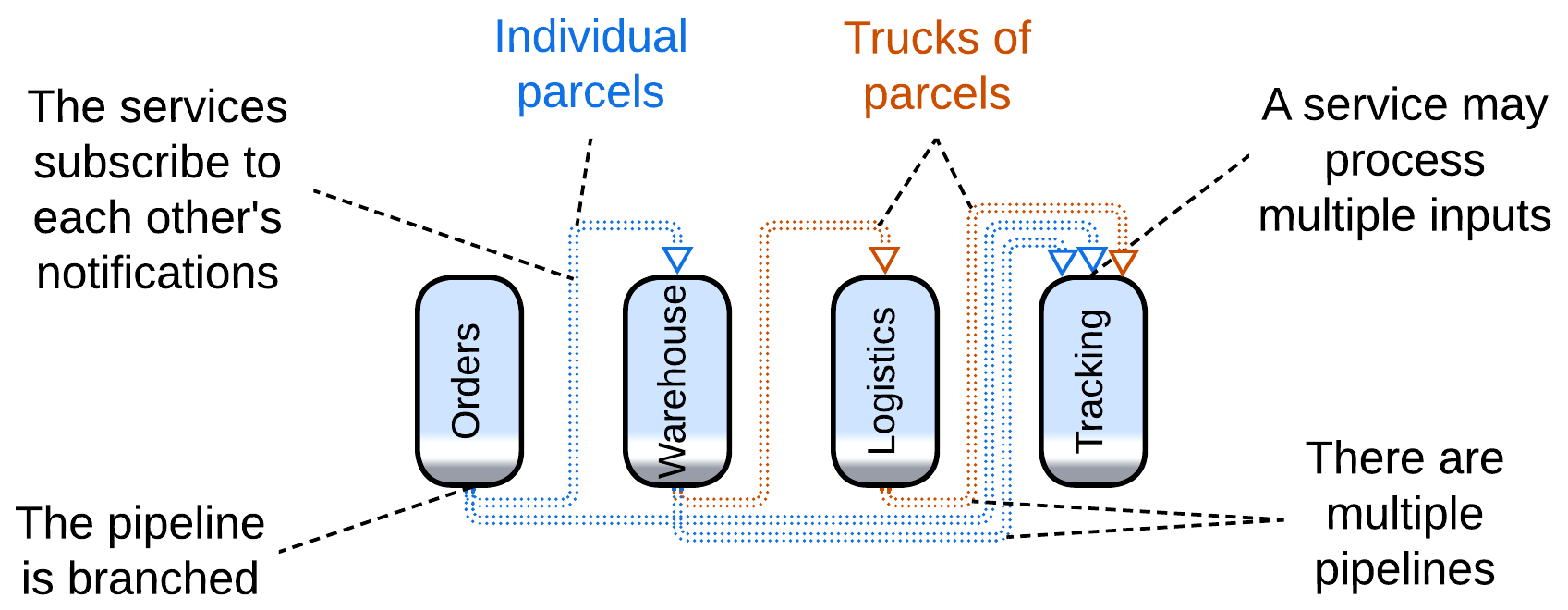
Relaxing the type and loosening the identity clauses opens the way to Choreographed Event-Driven Architecture [SAP, FSA], in which a service publishes notifications about anything it does that may be of interest to other services. In such a system:
- There are multiple types of events going in different directions, like if several branched pipelines were built over the same set of services.
- A service may aggregate multiple incoming events to publish a single, seemingly unrelated, event later when some condition is met. For example, a warehouse delivery collects individual orders till it gets a truckload of them or until the evening comes and no new orders are accepted.
This architecture covers way more complex use cases than Pipes and Filters as multiple pipelines are present in the system and because processing an event is allowed to have loosely related consequences (as with the parcel and truck).
Command Query Responsibility Segregation (CQRS) #
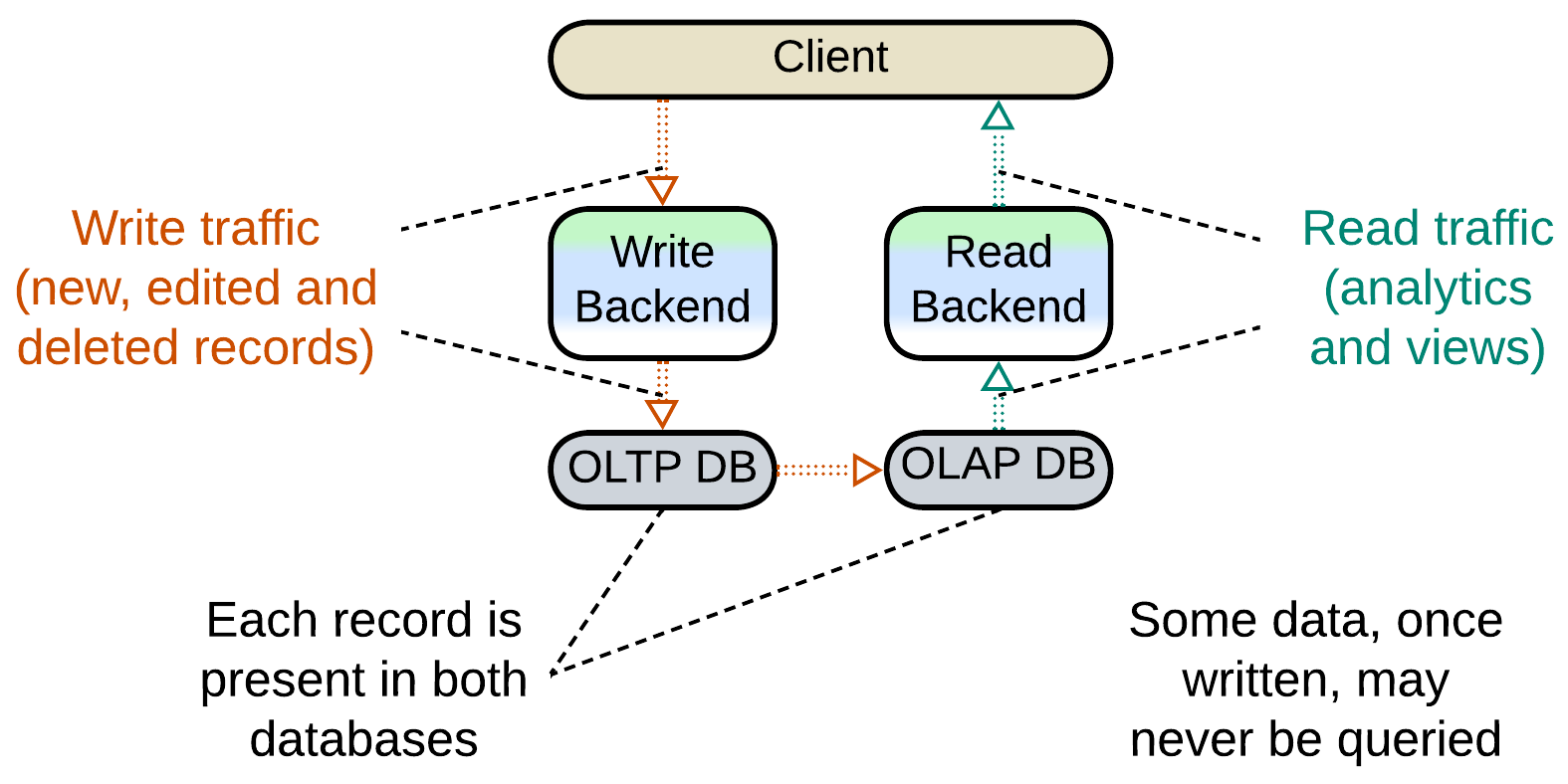
When data from events is stored for a future use (as with the aggregation above), the type and temporal order are ignored but data identity may be retained. A CQRS-based system [MP] separates paths for write (command) and read (query) requests, making a kind of data processing pipeline with the database in the middle, which stores events for an indeterminate amount of time. It is the database that reshuffles the order of events, as a record it stores may be queried at any time, maybe in a year from its addition – or never at all.
Model-View-Controller (MVC) #
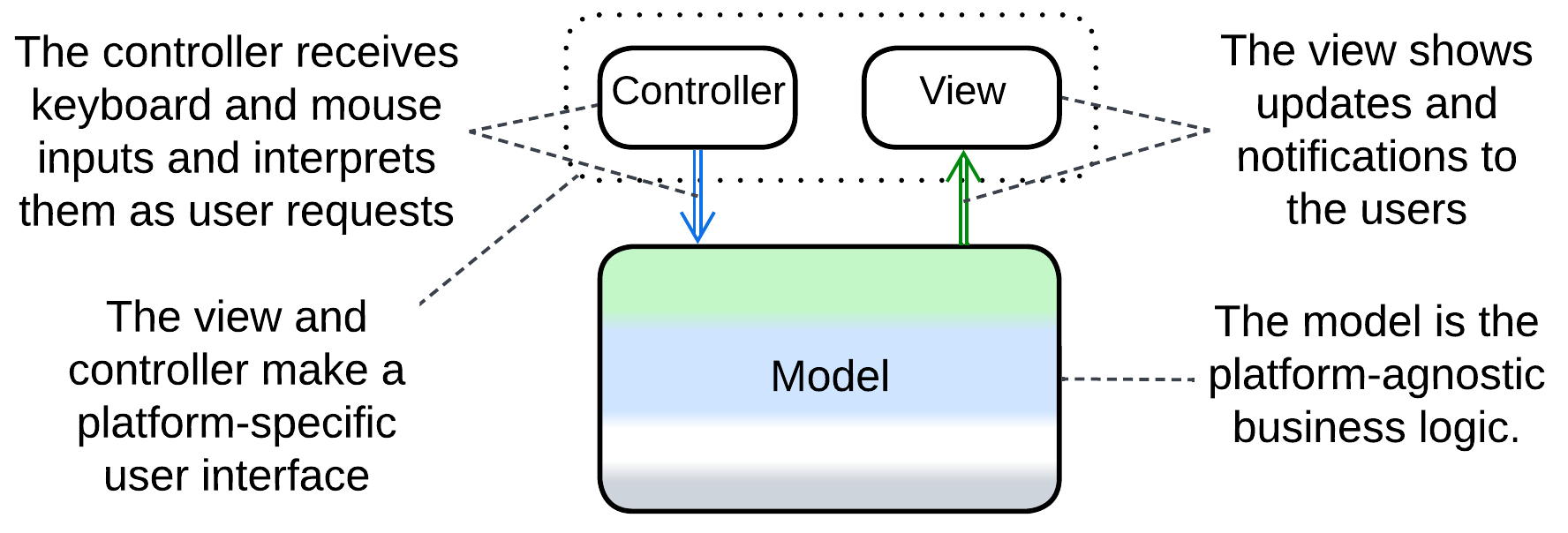
Model-View-Controller [POSA1] completely neglects the type and identity limitations. It is a coarse-grained pattern where the input source produces many kinds of events that go to the main module which does something and outputs another stream of events of no obvious relation to the input. A mouse click does not necessarily result in a screen redraw, while a redraw may happen on timer with no user actions. In fact, the pattern conjoins two different short pipelines.
Summary #
There are four architectures with unidirectional data flow, which is characteristic of pipelines:
- Pipes and Filters,
- Choreographed Event-Driven Architecture (EDA),
- Command (and) Query Responsibility Segregation (CQRS),
- Model-View-Controller (MVC).
The first two, being true pipelines, are built around data processing and transformation, while for the others it is just an aspect of implementation – their separation of input and output yields pairs of streams.