Mesh #
Hive mind. Go decentralized.
Known as: Mesh, Grid.
Aspects: those of Middleware.
Variants: Meshes vary greatly. Examples include:
- Peer-to-Peer Networks,
- Leaf-Spine Architecture / Spine-Leaf Architecture,
- Actors,
- Service Mesh [FSA, MP],
- Space-Based Architecture [SAP, FSA].
Structure: A system of interconnected Shards which usually make a Middleware.
Type: Implementation.
| Benefits | Drawbacks |
|---|---|
| No single point of failure | Overhead in administration and security |
| The system is able to self-heal | Performance is likely to suffer |
| Great scalability | The Mesh itself is very hard to debug |
| Available off the shelf | Unreliable communication must be accounted for in the code |
References: Wikipedia and [DDIA] on topology and protocols. [FSA] on Service Mesh and Space-Based Architecture. A long and short article on Service Mesh.
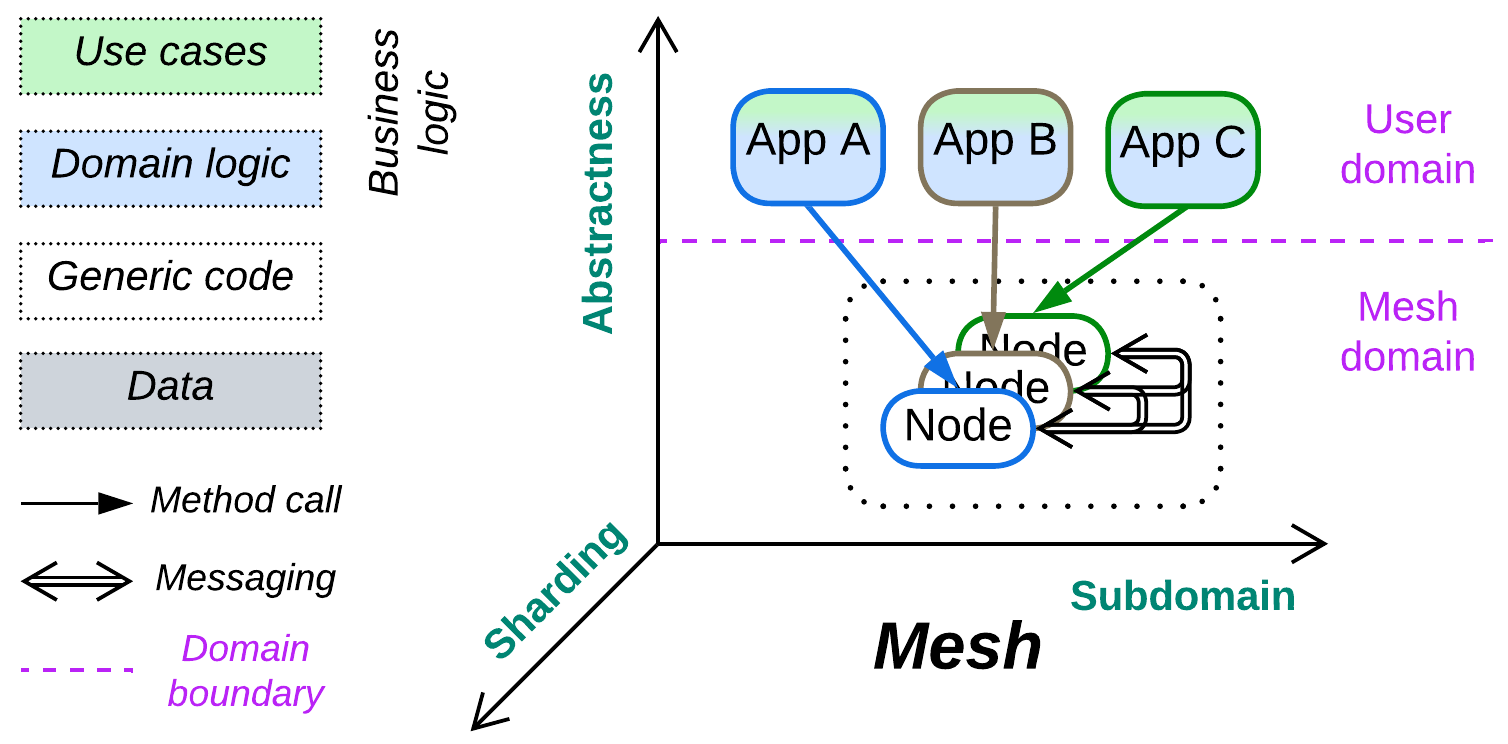
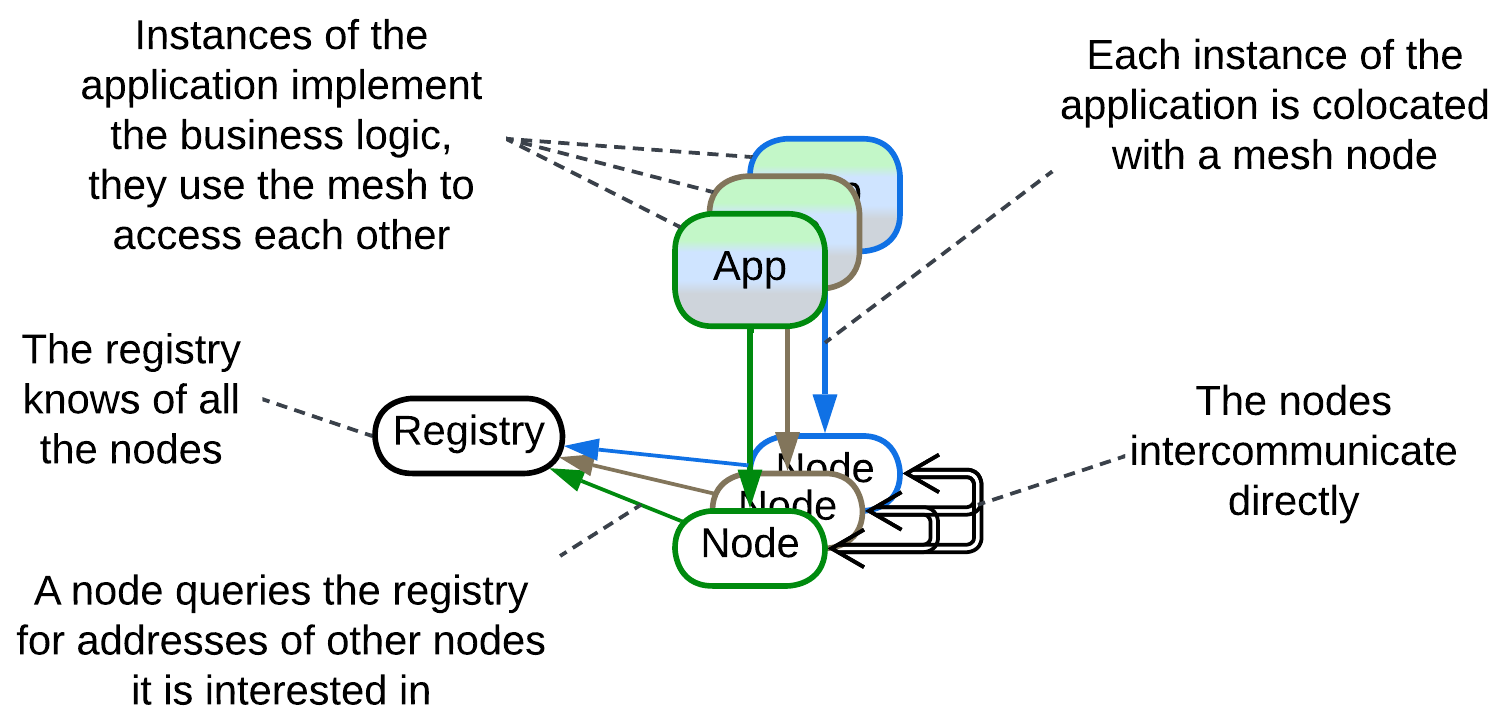
If a system is required to survive faults, all of its components must be both sharded and interconnected, which makes a Mesh – a network of interacting instances (nodes). In most cases the lower layer of a shard implements connectivity while the business logic resides in its upper layer(s). Whilst the connectivity component tends to be identical in every node of a system, the upper components may be identical – forming Shards, or different – forming Services.
Most Meshes support adding and removing parts of their networks dynamically, which allows for scaling up, scaling down, and fault recovery. That is achieved through a flexible network topology, which has the chance of missing or duplicating requests, which may lead to a single action being executed by two instances of a service in parallel or by the same instance twice. Moreover, Mesh-mediated communication is likely to be slower than direct one.
Performance #
In most (all?) implementations the user application is colocated with a node of the Mesh, thus communicating through the Mesh does not add an extra network hop (which would strongly degrade performance). However, that holds true only when the Mesh node knows the destination of the message it should send – when it has already established a communication channel towards it. Finding a new destination may not always be easy and would often require consulting registries and sometimes waiting for the network topology to stabilize, which may involve timeouts (like the ones you could have experienced with torrents). On the other hand, no other architecture is known to seamlessly support huge networks.
Dependencies #
Mesh, being a sharded Middleware, inherits dependencies from both of its parent metapatterns:
- As with Middleware, the services that run over a Mesh depend both on the Mesh’s API and on each other (or on a shared message format, aka Stamp Coupling, or a Shared Database if they use one for communication).
- As with Shards, the nodes of the Mesh should communicate through a backward- and forward-compatible protocol as there will likely be periods of time when multiple versions of the Mesh nodes coexist.
Applicability #
Mesh is perfect for:
- Dynamic scaling. Instances of services may be quickly added or removed.
- High availability. A Mesh is very hard to disable or kill because it both creates new instances of failed services and finds routes around failed connections.
Mesh fails in:
- Low latency domains. Spreading information through a Mesh is slow and sometimes unreliable.
- Security-critical systems. A public Mesh exposes a high attack surface while the scalability of private deployments is limited by the installed hardware.
- Quick and dirty programming. The possible message duplication may cause evil bugs if you ignore the risks.
Relations #
Mesh:
- Misuses Shards.
- Uses Layers.
- Is the base for running multiple instances of a Monolith, Layers, or Services.
- Implements a distributed Middleware, Shared Repository, or Microkernel.
Variants #
Meshes are known to vary:
By structure #
The connections in a Mesh may be:
- Structured or pre-defined – the Mesh is pre-designed and hard-wired. This kind of topology provides redundancy but not scalability.
- Unstructured or ad-hoc – nodes can be added and removed at runtime, causing restructuring of the Mesh.
By connectivity #
Each node is:
- Connected to all other nodes – a fully connected Mesh. Such Meshes are limited in size because the number of interconnections grows as a square of the number of nodes. Notwithstanding, they offer the best communication speed and delivery guarantees.
- Connected to some other nodes. There are many possible topologies with the correct choice for any given task better left to experts.
By the number of mesh layers #
The connected nodes of a Mesh may be:
- Identical (one-layer Mesh). A node behaves according to its site in the network.
- Specialized (multi-layer Mesh). Some nodes implement trunk (route messages and control the topology) while others are leaves (run user applications).
Examples #
Peer-to-Peer Networks #
Peer to Peer (P2P) networks are intended for massive resource sharing over unstable connections. The resource in question may be data (torrents, blockchain, P2PTV), CPU time (volunteer computing, distributed compilation), or Internet access (Tor, I2P). In most cases it is shared over an unstructured (as participants join and leave) 2-layer (there are dedicated servers that register and coordinate users) network which is overlaid on top of the Internet. All the leaf nodes run identical narrowly specialized software (i.e. either file sharing or blockchain but not both at once) which provides the clients with access to resources of other nodes, making a kind of distributed Middleware or Shared Repository.
Examples: torrent, onion routing (Tor), blockchain.
Leaf-Spine Architecture, Spine-Leaf Architecture #
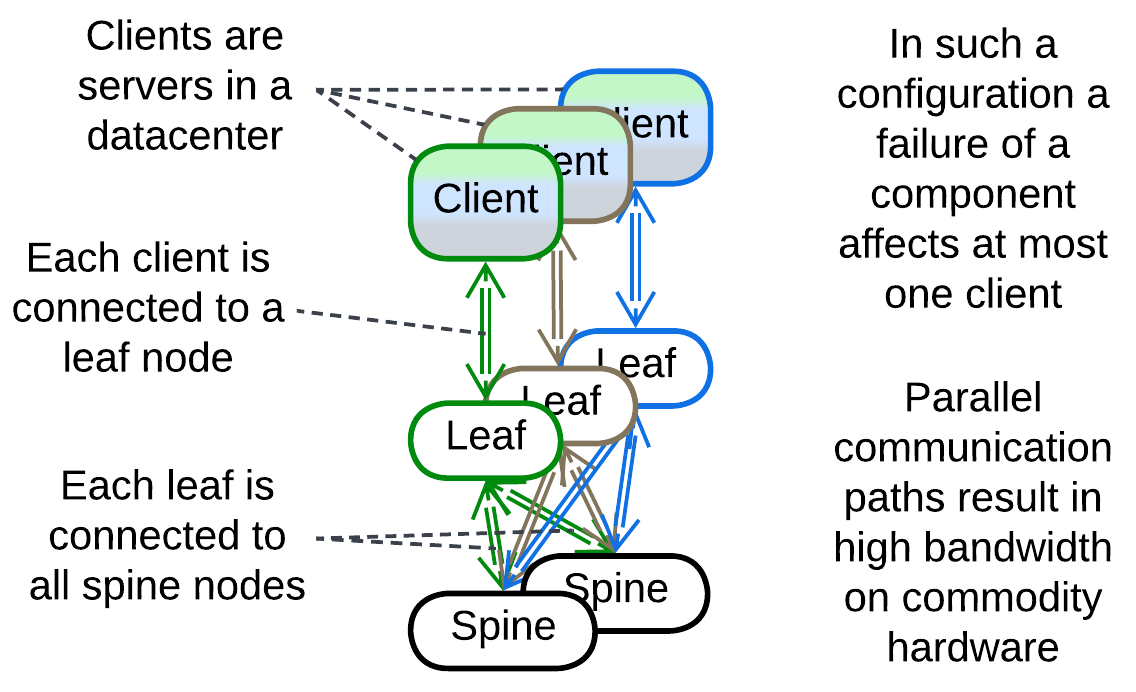
This datacenter network architecture is a rare example of a structured fully connected Mesh. It consists of client-facing (leaf) and internal (spine) switches. Each leaf is connected to every spine, allowing for very high bandwidth (by distributing the traffic over multiple routes) that is almost insensitive to failures of individual hardware as there are always many parallel connections.
Actors #
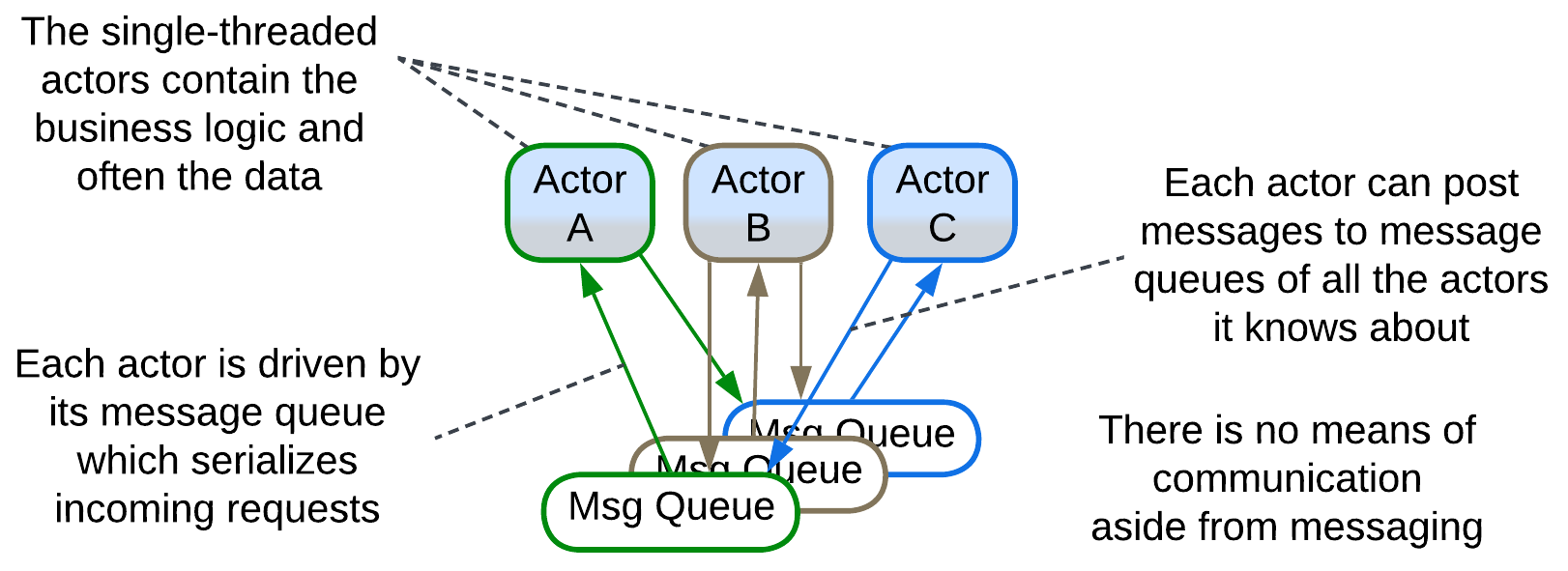
A system of Actors may be classified as a fully connected Mesh with the actors’ message queues being the nodes of the Mesh. Any actor can post messages to the queue of any other actor it knows about, as all the actors share a virtual namespace or physical address space.
Service Mesh #
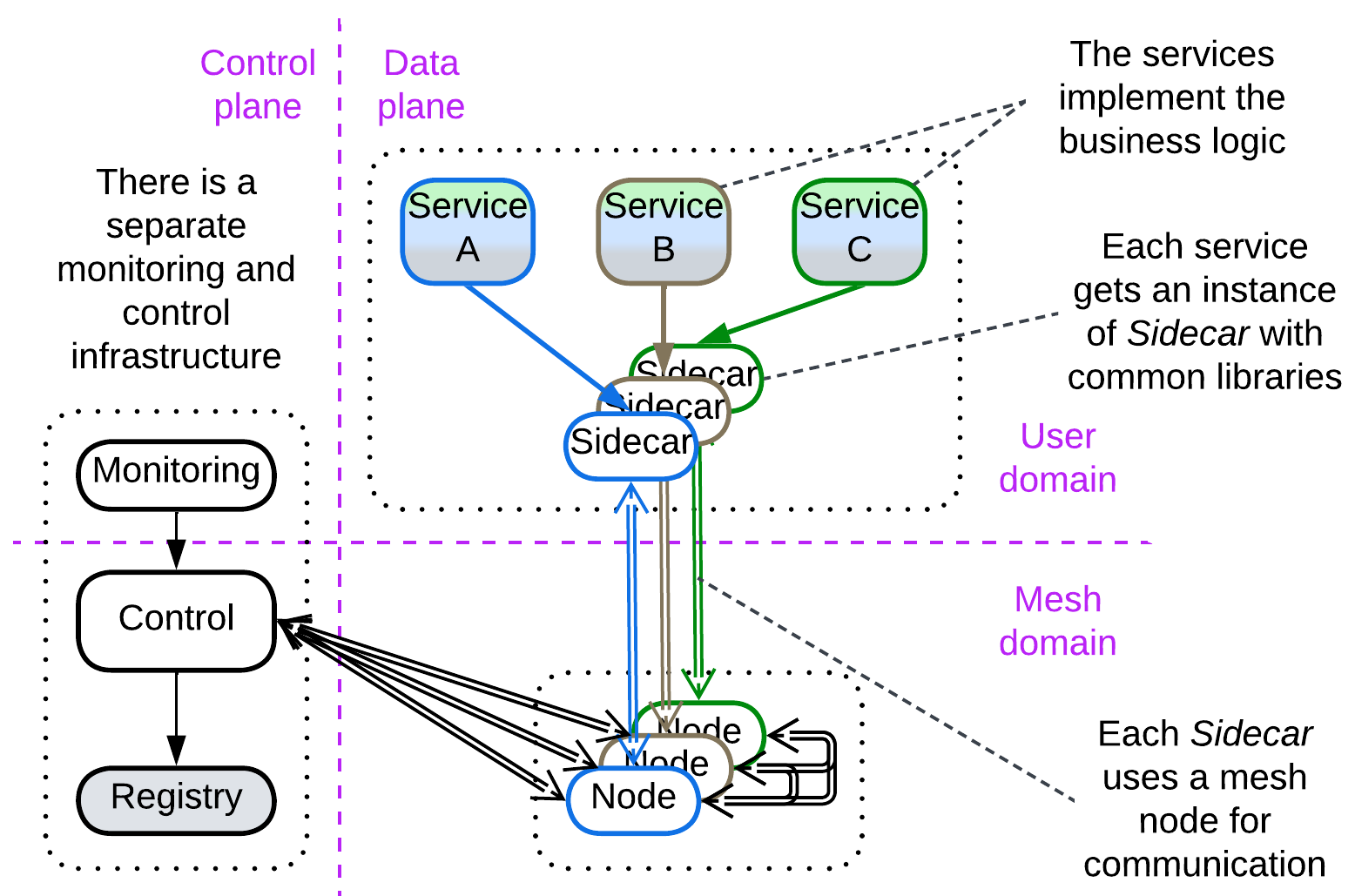
A Service Mesh [FSA, MP] is a distributed Middleware for running Microservices. It is a 2-layer Mesh which contains one or few management nodes (control plane) and many user nodes (data plane). Each data plane node colocates:
- A mesh engine node that deals with connectivity,
- One or more Sidecars [DDS] (Proxies where the support of cross-cutting concerns – the identical code for use by every service, e.g. logging or encryption – resides),
- A user application (microservice) that differs from node to node.
The control plane (re-)starts, updates, scales, and collects statistics from the nodes of the data plane.
Service Mesh addresses some of the weaknesses of naive Services: it provides tools for centralized management and allows for virtual sharing (through creating physical copies) of libraries to be accessed by all the service instances. It also takes care of scaling and load balancing.
Ready-to-use Service Mesh frameworks are popular with the Microservices architecture.
Space-Based Architecture #
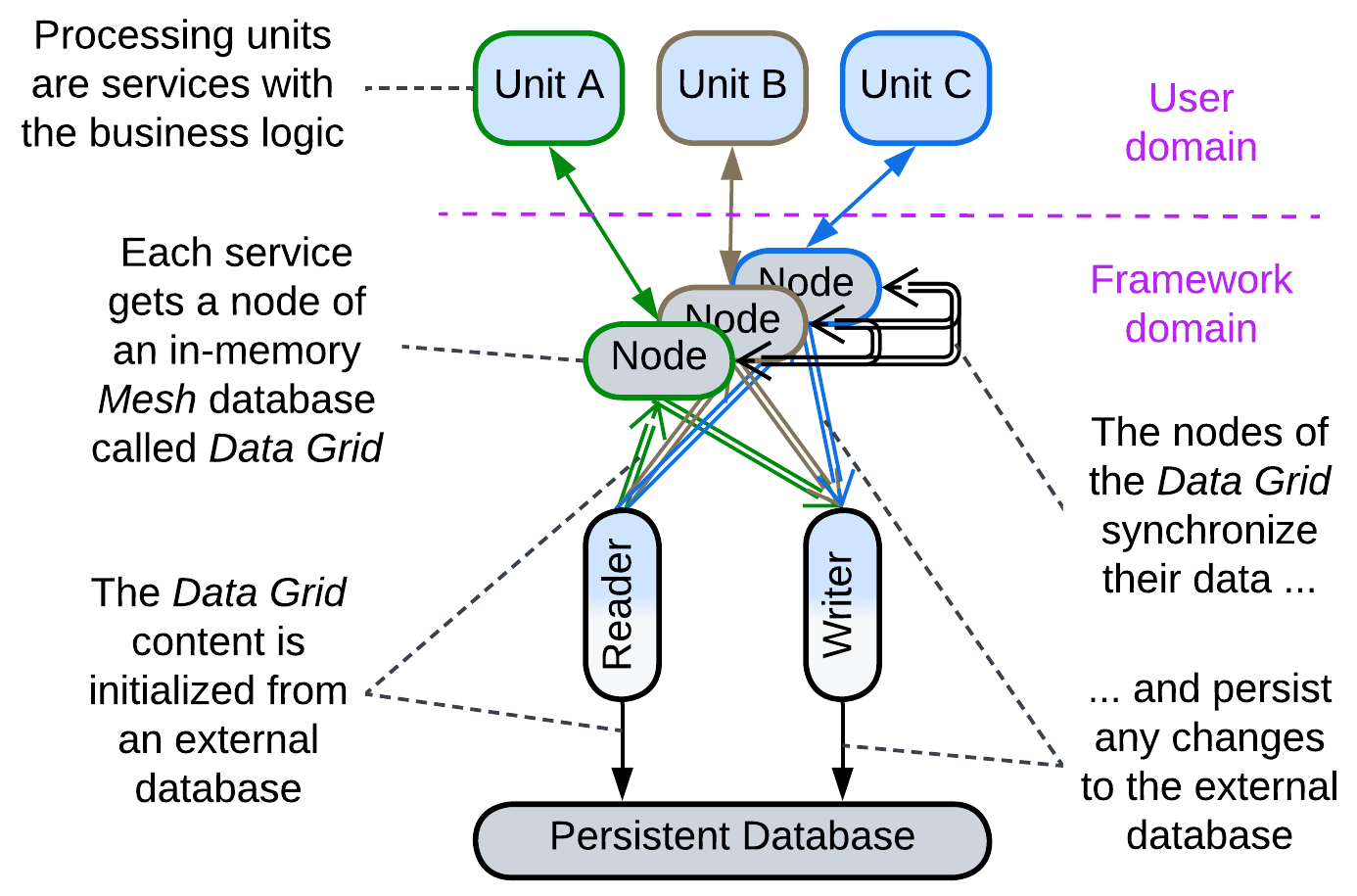
Space-Based Architecture [SAP, FSA] is a kind of Service Mesh with an integrated Shared Repository (a tuple space – shared dictionary – called Data Grid) and an Orchestrator (called Processing Grid). The user services are called Processing Units. They may be identical (making Shards) or different (resulting in Services). This architecture is used for:
- Highly scalable systems with relatively small datasets in which case the entire database contents are replicated in the memory of each node. This works around the throughput and latency limits of a normal database.
- Huge datasets, with each node owning a part of the total data. This hacks around the storage capacity and latency limits of a database which may even be kept out of the loop, leaving the Mesh as the only data storage.
There are multiple instances of the same data in Processing Units. Any change to the data in one unit must propagate to other units. That can be done in several ways:
- Asynchronously, causing conflicts if the same data is changed elsewhere simultaneously.
- Synchronously, waiting for the propagation results and conflict resolution – a kind of distributed transaction which has poor latency.
- The unit takes write ownership of the data before the write. That is not good for latency as well, but it may be a good choice for an evenly distributed load if the Mesh engine provides temporary locality of requests, i.e. it forwards requests that touch the same data to the same node.
The choice of the strategy depends on your domain.
The in-memory data in the nodes is usually loaded from a Persistent Database on initialization of the system and any change to the data is replicated asynchronously back to the Persistent Database, which serves as a means of fault recovery in the unlikely case the entire Mesh goes down.
Summary #
Mesh is a layer of intercommunicating instances of an infrastructure component that makes a foundation for running custom services in a distributed environment. This architecture is famous for its scalability and fault tolerance but is too complex to implement in-house and may incur performance, administration and development overhead.