Polyglot Persistence #
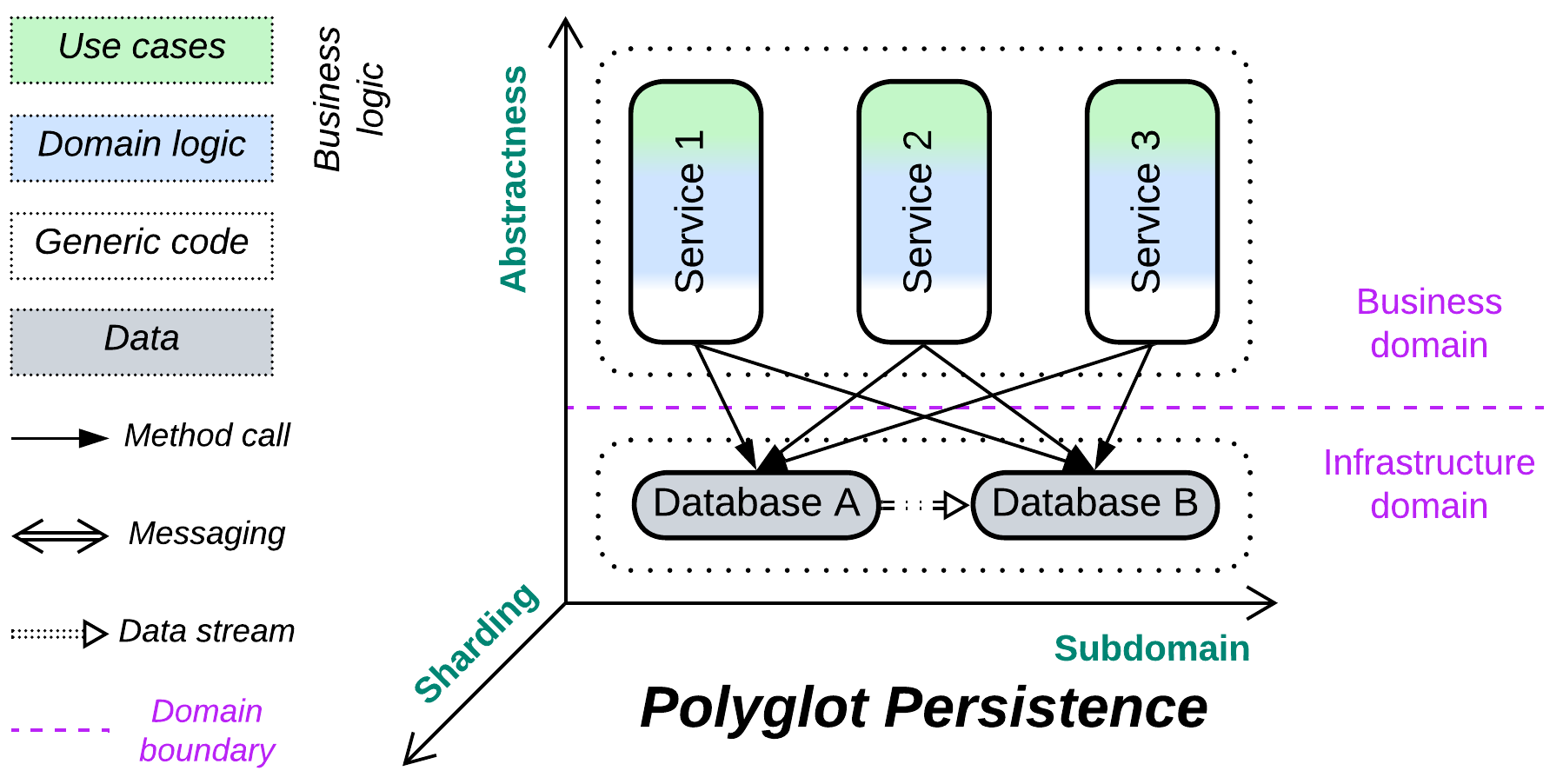
Unbind your data. Use multiple specialized databases.
Known as: Polyglot Persistence.
Aspects: those of the databases involved.
Variants:
Independent storage:
- Specialized Databases,
- Private and Shared Databases,
- Data File / Content Delivery Network (CDN).
Derived storage:
- Read-Only Replica,
- Reporting Database / CQRS View Database [MP] / Event-Sourced View [DEDS] / Source-Aligned (Native) Data Product Quantum (DPQ) of Data Mesh [SAHP],
- Memory Image / Materialized View [DDIA],
- Query Service [MP] / Front Controller [SAHP but not PEAA] / Data Warehouse [SAHP] / Data Lake [SAHP] / Aggregate Data Product Quantum (DPQ) of Data Mesh [SAHP],
- External Search Index,
- Historical Data / Data Archiving,
- Database Cache / Cache-Aside.
Structure: A layer of data services used by higher-level components.
Type: Extension, derived from Shared Repository.
| Benefits | Drawbacks |
|---|---|
| Performance is fine-tuned for various data types and use cases | The peculiarities of each database need to be learned |
| Less load on each database | Muсh more work for the DevOps team |
| The databases may satisfy conflicting forces | More points of failure in the system |
| Consistency is hard or slow to achieve |
References: The original and closely related CQRS articles from Martin Fowler, chapter 7 of [MP], chapter 11 of [DDIA] and much information dispersed all over the Web.
You can choose a dedicated technology for each kind of data or pattern of data access in your system. That improves performance (as each database engine is optimized for a few use cases), distributes load between the databases, and may solve conflicts between forces (like when you need both low latency and large storage). However, you’ll likely have to hire several experts to get the best use of and to support the multiple databases. Moreover, having your data spread over multiple databases makes it the application’s responsibility to keep the data in sync (by implementing some kind of distributed transactions or making sure that the clients don’t get stale data).
Performance #
Polyglot Persistence aims at improving performance through the following means:
- Optimize for specific data use cases. It is impossible for a single database to be good at everything.
- Redirect read traffic to read-only database replicas. The write-enabled leader database then processes only the write requests.
- Cache any frequently used data in a fast in-memory database to let the majority of client requests be served without hitting the slower persistent storage.
- Build a view of the states of other services in the system to avoid querying them.
- Maintain an external index or Memory Image for use with tasks that don’t need the history of changes.
- Purge old data to a slower storage.
- Store read-only sequential data as files, often close to the end users who download them.
Read-write separation introduces a replication lag which is a pain when data consistency is important for the system’s clients.
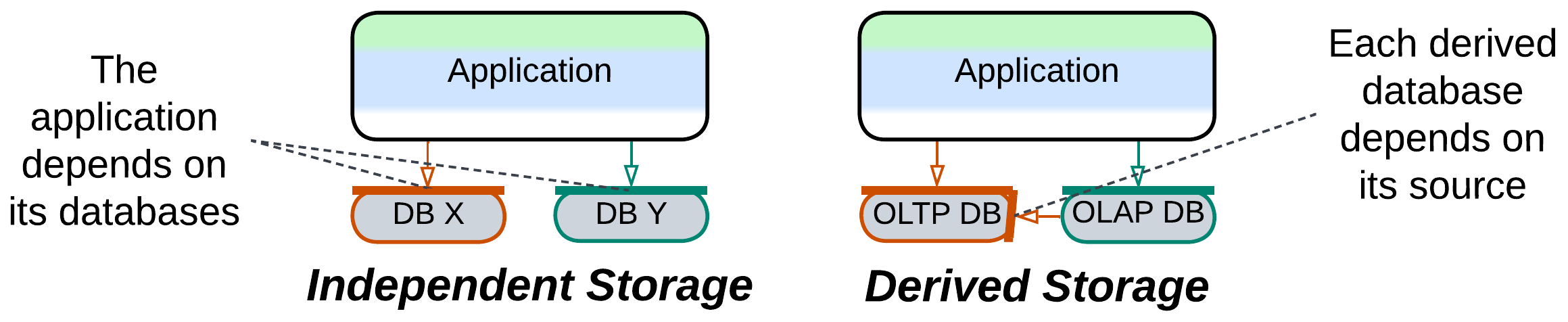
Dependencies #
In general, each service depends on all of the databases which it uses. There may also be an additional dependency between the databases if they share a dataset (one or more databases are derived).
Applicability #
Polyglot Persistence helps:
- High load and low latency projects. Specialized Databases shine when given fitting tasks. Caching and Read-Only Replicas take the load off the main database. External Search Indices save the day.
- Event sourcing. Materialized Views maintain the current states of the system’s components.
- Conflicting forces. An instance of a stateless service inherits many of the qualities of the database which it accesses for any given request it is processing. When there are several databases, the qualities of a service instance may vary from request to request,depending on which database is involved.
Polyglot Persistence may harm:
- Small projects. Properly setting up and maintaining multiple databases is not that easy.
- High availability. Each database which your system uses will tend to fail in its own crazy way.
- User experience. For systems with read-write database separation the replication lag between the databases will make you choose between reading changes from the leader (write database), adding synchronization code to your application to wait for the read database to be updated, and risking returning outdated results to the users.
Relations #
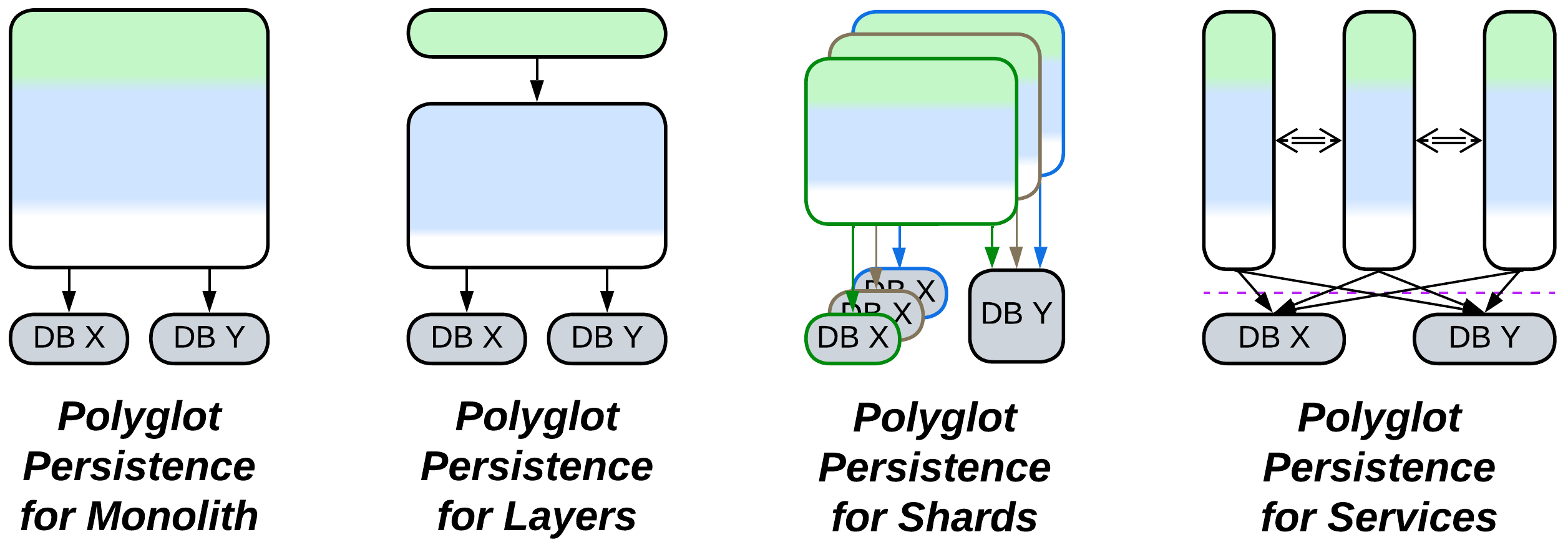
Polyglot Persistence:
- Extends Monolith, Shards, Layers, or Services.
- Is derived from Layers (persistence layer) or Shared Repository.
- Variants with derived databases have an aspect of Pipeline and are closely related to CQRS.
Variants with independent storage #
Many cases of Polyglot Persistence use multiple datastores just because there is no single technology that matches all the application’s needs. The databases used are filled with different subsets of the system’s data:
Specialized Databases #
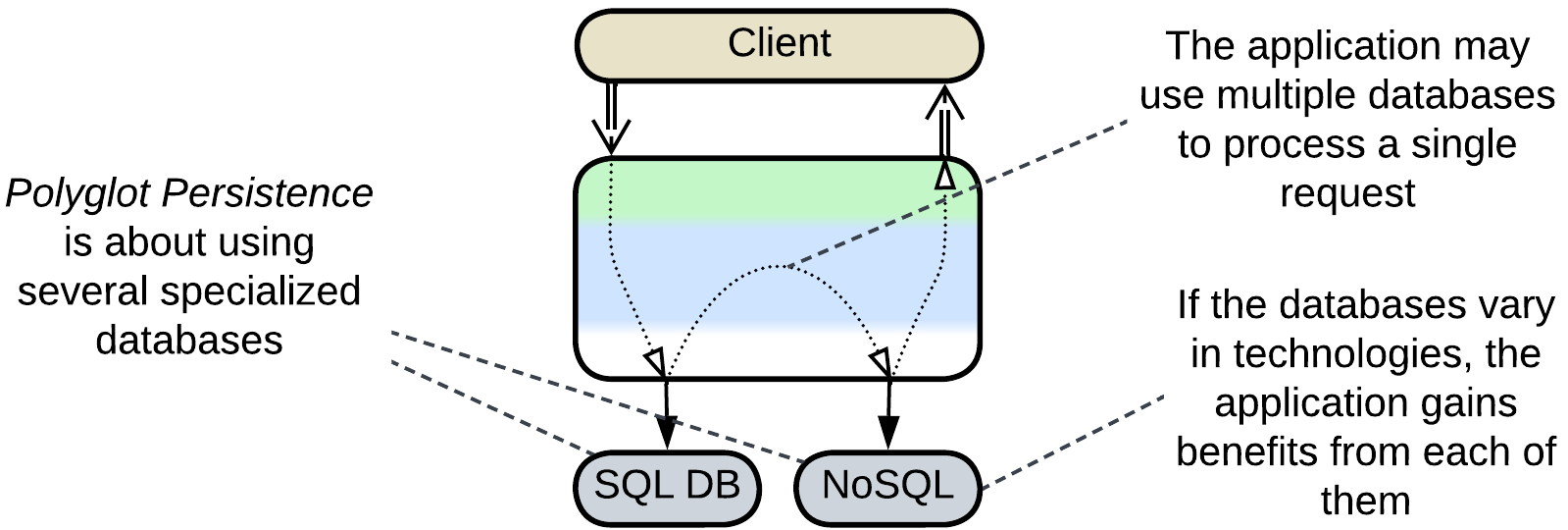
Databases vary in their optimal use cases. You can employ several different databases to achieve the best performance for each kind of data that you persist.
Private and Shared Databases #
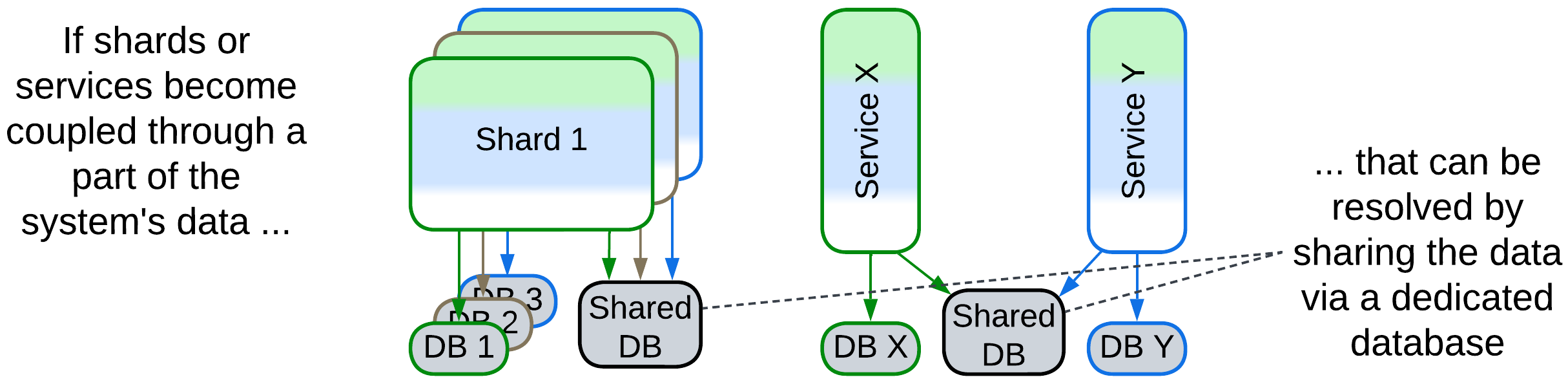
If several services or shards become coupled through a subset of the system’s data, that subset can be put into a separate database which is accessible to all the participants. All the other data remains private to the shards or services.
Data File, Content Delivery Network (CDN) #
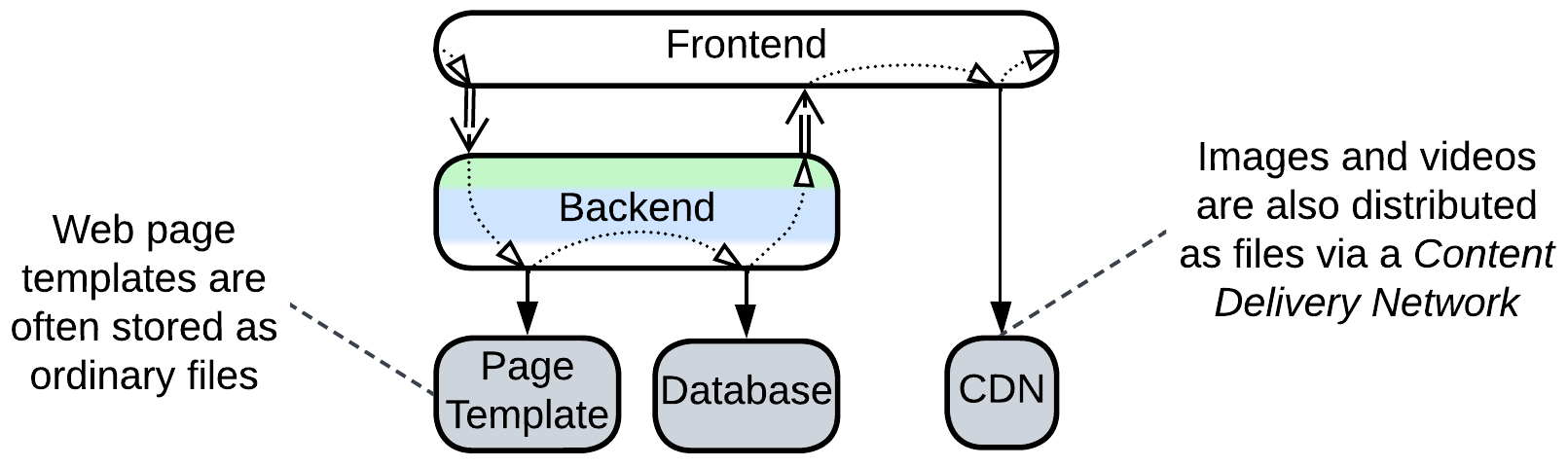
Some data is happy to stay in files. Web frameworks load web page templates from OS files and store images and videos in a Content Delivery Network (CDN) which replicates the data all over the world so that each user downloads the content from the nearest server (which is faster and cheaper).
Variants with derived storage #
In other cases there is a single writable database (system of record [DDIA]) which is the main source of truth from which the other databases are derived. The primary reason to use several databases is to relieve the main database of read requests and maybe support some additional qualities: special kinds of queries, aggregation for materialized and CQRS views, full text search for text indices, huge dataset size for historical data or low latency for an in-memory cache.
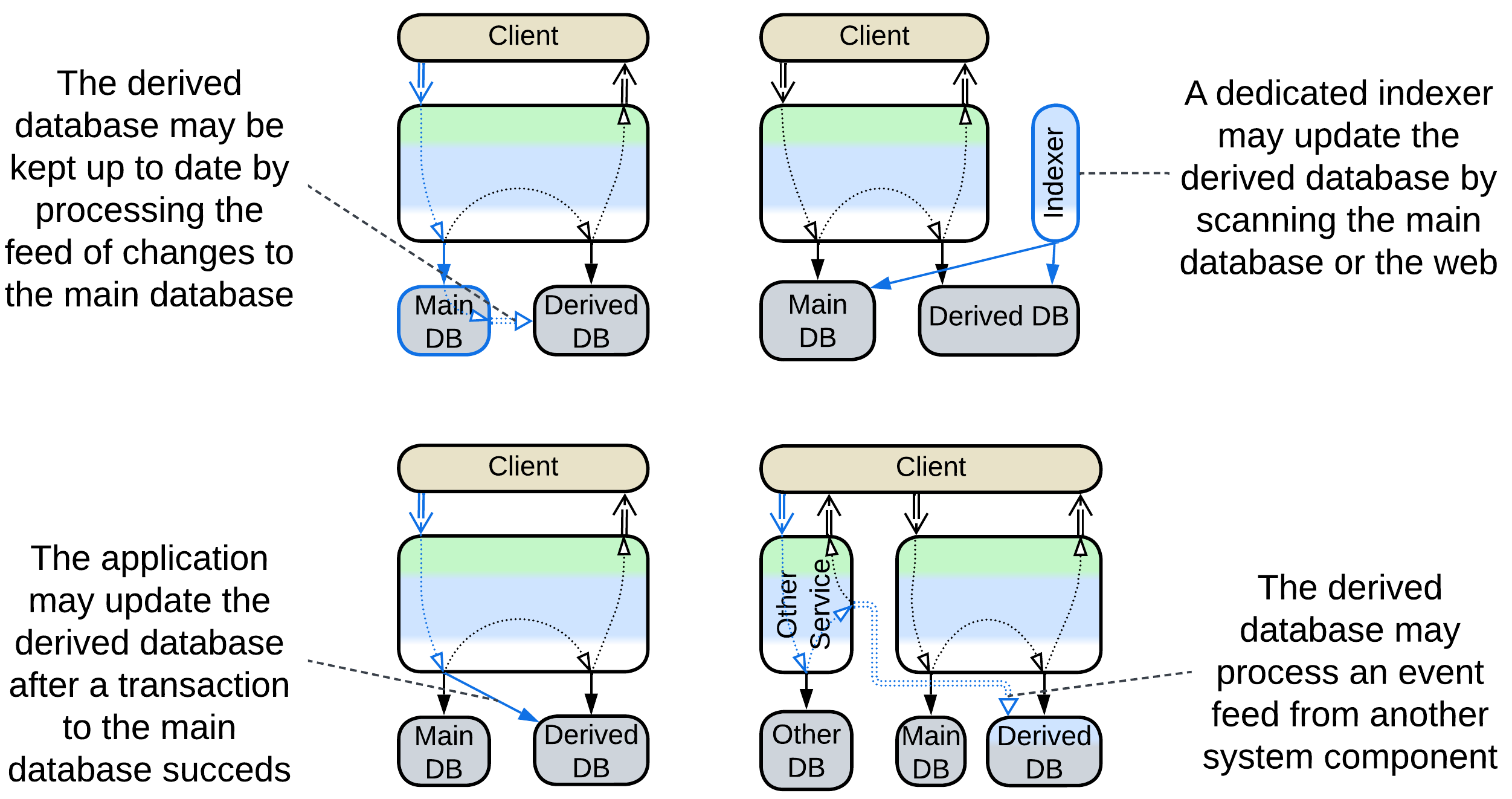
The updates to the derived databases may come from:
- the main database as Change Data Capture (CDC) [DDIA] (a log of changes),
- the application after it changes the main database (see caching strategies below),
- another service as event stream [DDIA, MP],
- a dedicated indexer that periodically crawls the main database or web site.
Read-Only Replica #
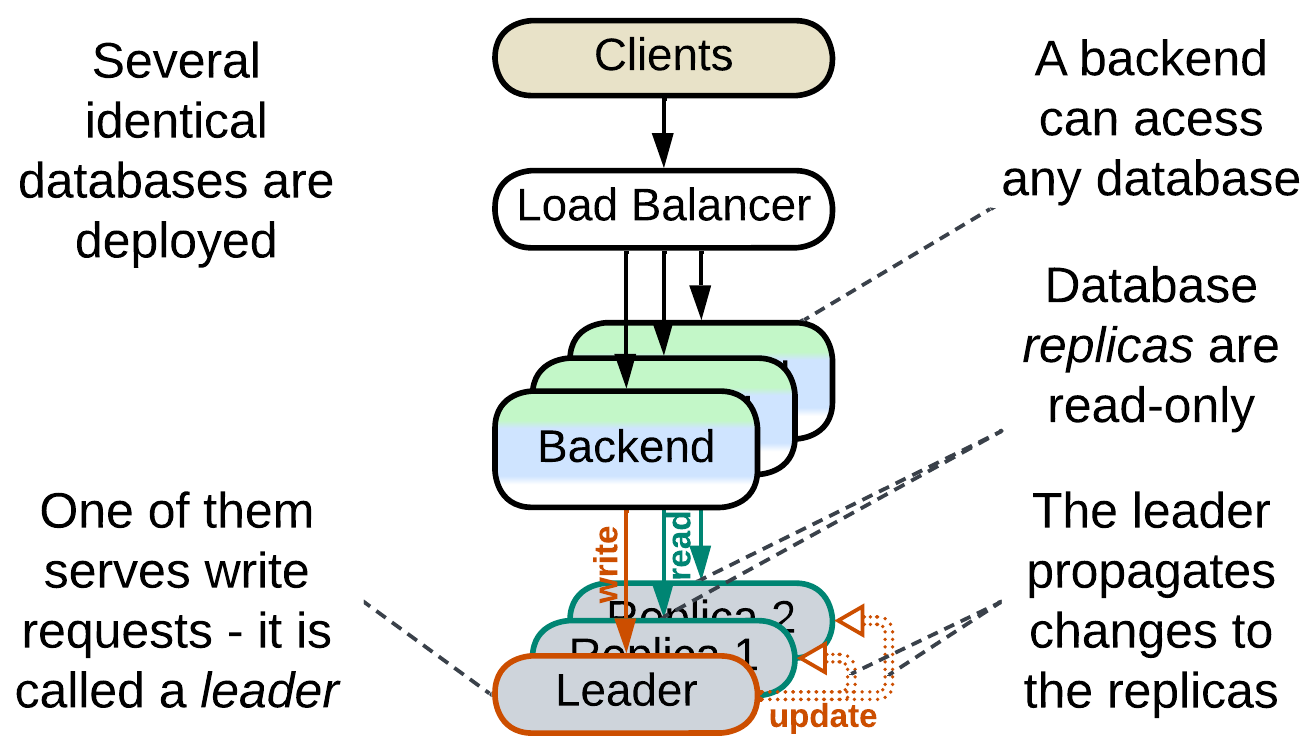
Multiple instances of the database are deployed and one of them is the leader [DDIA] instance which processes all writes to the system’s data. The changes are then replicated to the other instances (via Change Data Capture (CDC)) which are used for read requests. Distributing workload over multiple instances increases maximum read throughput which the system is capable of, as the database is usually the system’s bottleneck. Having several running replicas greatly improves reliability and allows for nearly instant recovery of database failures as any replica may quickly be promoted to the leader role to serve write traffic.
Reporting Database, CQRS View Database, Event-Sourced View, Source-Aligned (Native) Data Product Quantum (DPQ) of Data Mesh #
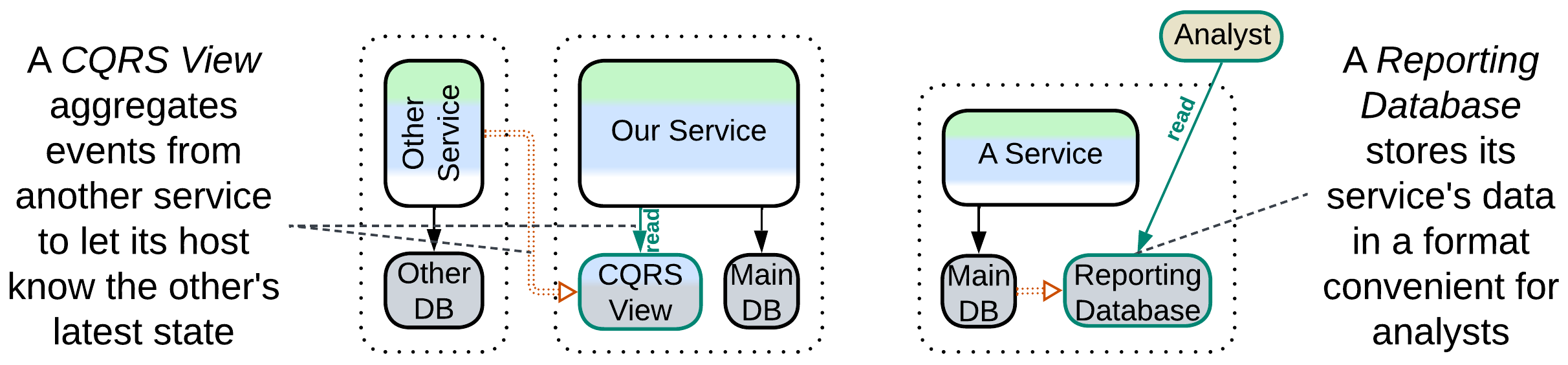
It is common wisdom that a database is good for either OLTP (transactions) or OLAP (queries). Here we have two databases: one optimized for commands (write traffic protected with transactions) and another one for complex analytical queries. The databases differ at least in schema (OLAP schema is optimized for queries) and often vary in type (e.g. SQL vs NoSQL).
A Reporting Database (or Source-Aligned (Native) Data Product Quantum of Data Mesh [SAHP]) derives its data from a write-enabled database in the same subsystem (service) while a CQRS View [MP] or Event-Sourced View [DEDS] is fed a stream of events from another service from which it filters the data relevant to its owner. This way a CQRS View lets its owner service query (its replica of) the data that originally belonged to other services.
Memory Image, Materialized View #
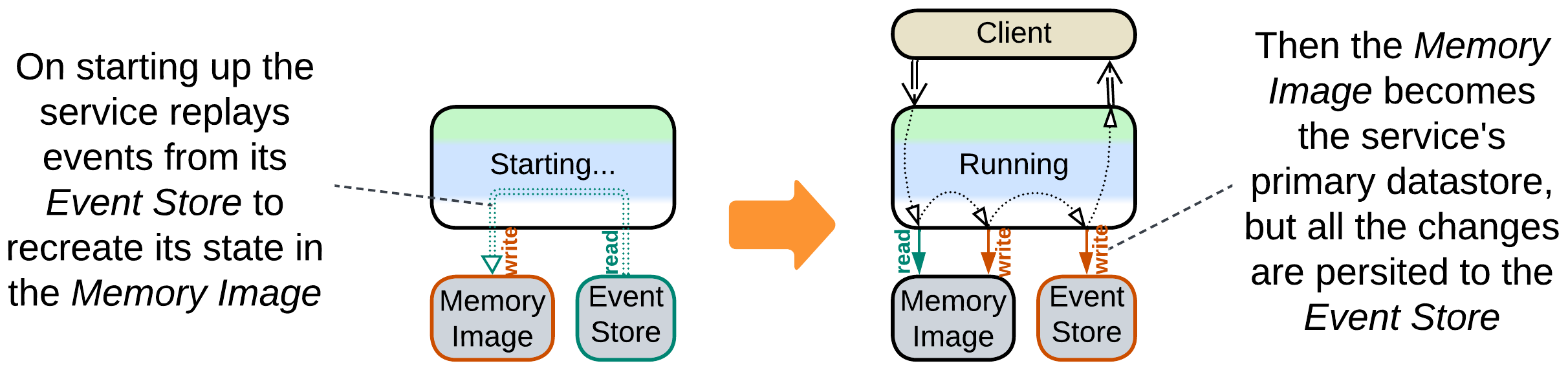
Event sourcing (of Event-Driven Architecture or Microservices) is all about changes. A service persists only changes to its data instead of the current data. As a result, the service needs to aggregate its history into a Memory Image (Materialized View [DDIA]) by loading a snapshot and replaying any further events to rebuild its current state (which other architectural styles store in databases) and start operating.
Query Service, Front Controller, Data Warehouse, Data Lake, Aggregate Data Product Quantum (DPQ) of Data Mesh #
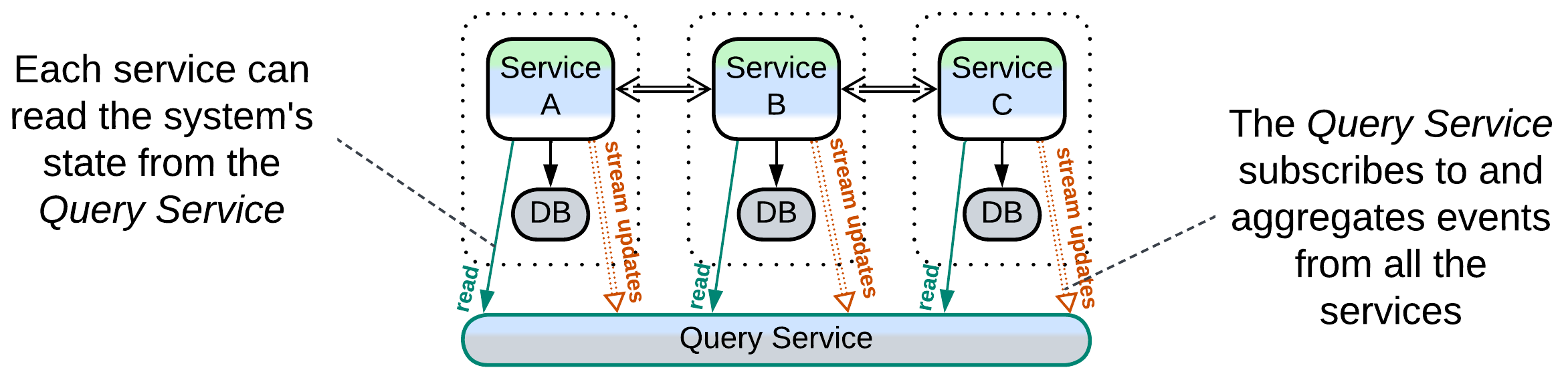
A Query Service [MP] (or Aggregate Data Product Quantum of Data Mesh [SAHP]) subscribes to events from several full-featured services and aggregates them into its database, making it a CQRS View of several services or even the whole system. If any other service or a data analyst needs to process data which belongs to multiple services, it retrieves it from the Query Service which has already joined the data streams and represents the join in a convenient way.
A Front Controller [SAHP but not PEAA] is a Query Service embedded in the first (user-facing) service of a Pipeline. It collects status updates from downstream components of the Pipeline to track the state of every request being processed by the Pipeline.
Data Warehouse [SAHP] and Data Lake [SAHP] are analytical databases that connect directly to and import all the data from the operational (main) databases of all the system’s services. A Data Warehouse translates the imported data into its own unified schema while a Data Lake stores the imported data in its original formats.
External Search Index #
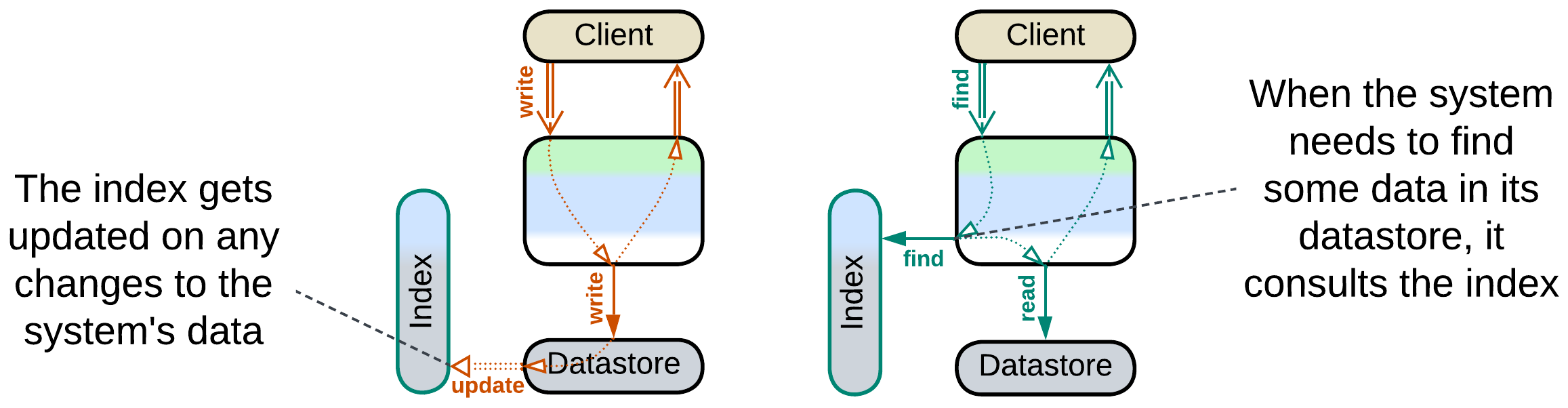
Some domains require a kind of search which is not naturally supported by ordinary database engines. Full text search, especially NLP-enabled, is one such case. Geospatial data may be another. If you are comfortable with your main database(s), you can set up an External Search Index by deploying a product dedicated to the special kind of search that you need and feeding it updates from your main database.
Historical Data, Data Archiving #
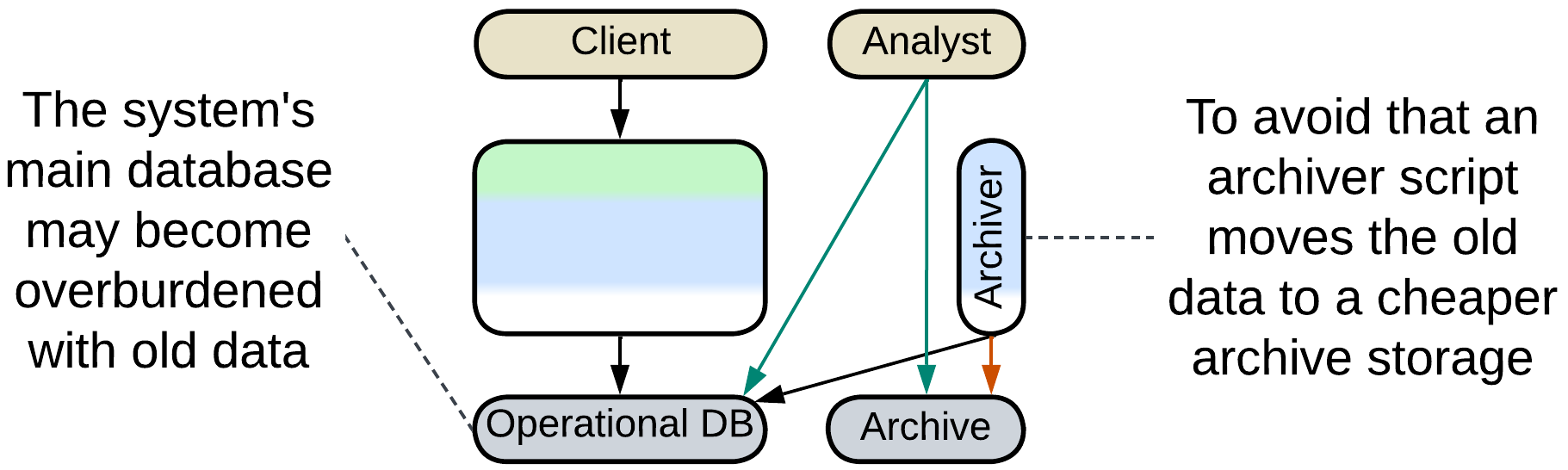
It is common to store the history of sales in a database. However, once a month or two has passed, it is very unlikely that the historical records will ever be edited. And though they are queried on very rare occasions, like audits, they still slow down your database. Some businesses offload any data older than a couple of months to a cheaper archive storage which does not allow changes to the data and has limited query capabilities in order to keep the main datasets small and fast.
Database Cache, Cache-Aside #
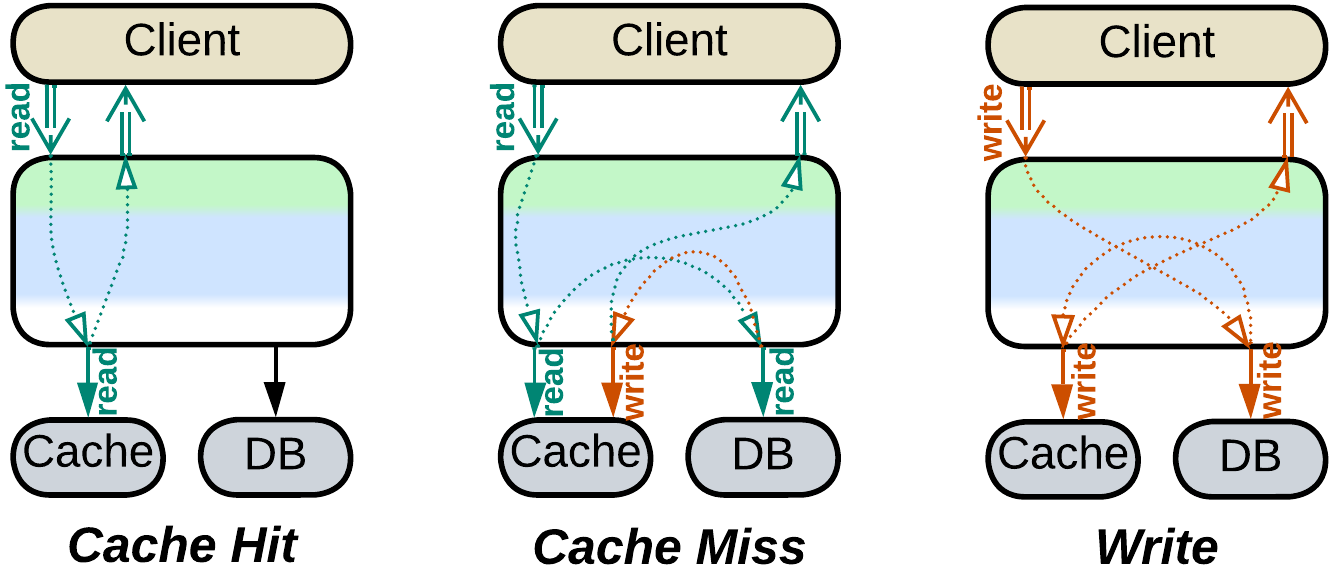
Database queries are resource-heavy while databases scale only to a limited extent. That means that a highly loaded system benefits from bypassing its main database with as many queries as possible, that is usually achieved by storing recent queries and their results in an in-memory database (Cache-Aside). Each incoming query is first looked for in the fast cache, and if it is found then you are lucky to get the result immediately without having to consult the main database.
Keeping the cache consistent with the main database is the hard part. There are quite a few strategies (some of them treat the cache as a Proxy for the database): write-through, write-behind, write-around and refresh-ahead.
Evolutions #
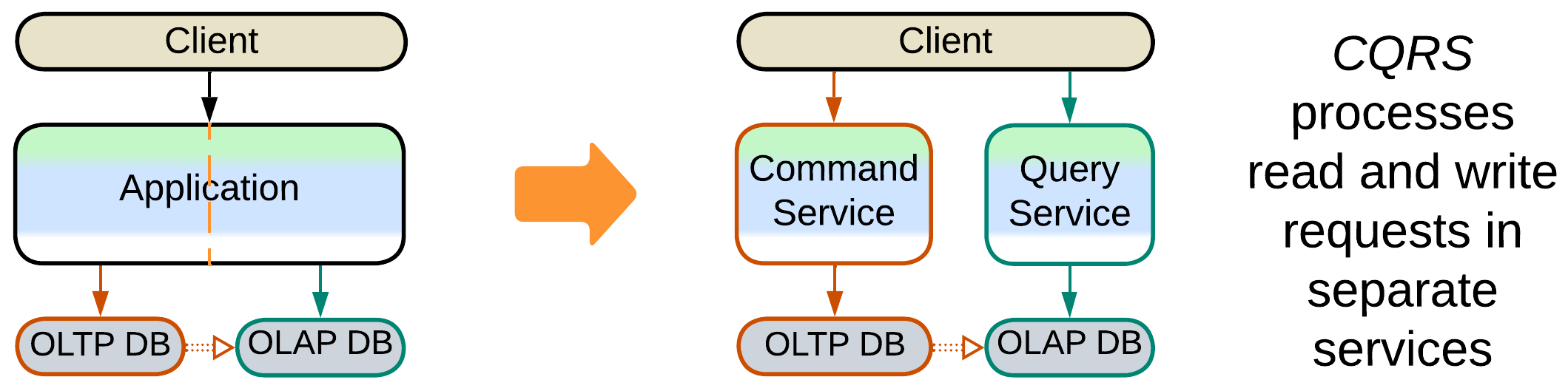
Polyglot Persistence with derived storage can often be made subject to CQRS:
- The service that uses the read and write databases is split into separate read and write services.
Summary #
Polyglot Persistence employs several specialized databases to improve performance, often at the cost of eventual data consistency or implementing transactions in the application.