Middleware #
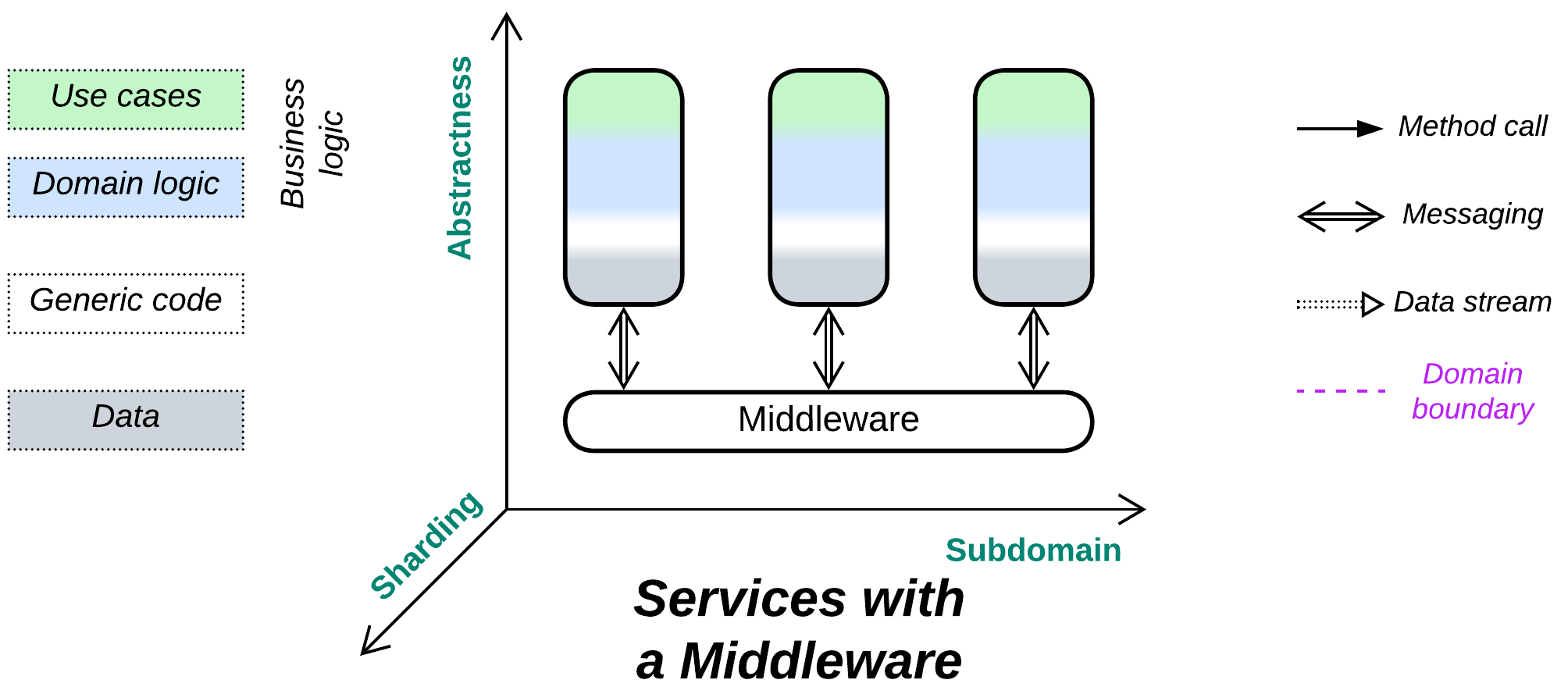
The line between disorder and order lies in logistics. Use a shared transport.
Known as: (Distributed) Middleware.
Aspects:
Variants: Implementations differ in many dimensions.
The following combined patterns include Middleware:
- (with Adapters) Message Bus [EIP],
- (with Proxies) Service Mesh [FSA, MP],
- (with an Orchestrator) Event Mediator [FSA],
- (with a Shared Repository) Persistent Event Log / Shared Event Store,
- (with an Orchestrator and Adapters) Enterprise Service Bus (ESB) [FSA].
Structure: A low-level layer that provides connectivity.
Type: Extension.
| Benefits | Drawbacks |
|---|---|
| Separates connectivity concerns from the services that use it | May become a single point of failure |
| Transparent scaling of components | May increase latency |
| Available off the shelf | A generic Middleware may not fit specific communication needs |
References: [EIP] has a lot of content on the implementation of messaging Middleware. [POSA4] features a chapter on Middleware. However, those books are old. [DEDS] is about Kafka, but it goes too far advertising it as a Shared Event Store. There is also a Wikipedia article.
Extracting transport into a separate layer relieves the components that implement business logic of the need to know the addresses and statuses of each other’s instances. An industrial-grade, third-party Middleware is likely to be more stable and provide better error recovery than anything an average company can afford to implement on its own.
A Middleware may function as:
- A Message Broker [POSA1, POSA4, EIP, MP] which provides a unified means of communication and implements some cross-cutting concerns like the persisting or logging of messages.
- A Deployment Manager [SAP, FSA] which collects telemetry and manages service instances for error recovery and dynamic scaling.
As Middleware is ubiquitous and does not affect business logic, it is usually omitted from structural diagrams.
Performance #
A Middleware may negatively affect performance when compared to direct communication between services. Old implementations (star topology) relied on a Broker [POSA1, POSA4, EIP] that used to add an extra network hop for each message and limited scalability. Newer Mesh-based variants avoid those drawbacks but are very complex and may have consistency issues (according to the CAP theorem).
A more subtle drawback is that transports supported or recommended by a Middleware may be suboptimal for some of the interactions in your system, causing programmers to hack around the limitations or build higher-level protocols on top of your Middleware. Both cases can be ameliorated by adding means for direct communication between the services to bypass the Middleware or by using multiple specialized kinds of Middleware. However, that adds to the complexity of the system – the very issue the Middleware promised to help with.
Dependencies #
Each service depends both on the Middleware and on the API of every service it communicates with.

You may decide to use an Anticorruption Layer [DDD] over your Middleware just in case you may need to change its vendor in the future.
Applicability #
Middleware helps:
- Multi-component systems. When a service has several instances deployed which need to be accessed, its clients must know the addresses of (or have channels to) its instances and use an algorithm for instance selection. As the number of services grows, so does the amount of information about the others that each of them needs to track. Even worse, services sometimes crash or are being redeployed, requiring complicated algorithms that queue messages to deliver them in order once the service returns to life. It makes all the sense to use a dedicated component that takes care of all of that.
- Dynamic scaling. It is good to have a single component that manages routes for interservice messaging to account for newly deployed (or destroyed) service instances.
- Blue-green deployment, canary release, or dark launching (traffic mirroring). It is easier to switch, whether fully or in part, to a new version of a service when the communication is centralized.
- System stability. Most implementations of Middleware guarantee message delivery with unstable networks and failing components. Many persist messages to be able to recover from failures of the Middleware itself.
Middleware hurts:
- Critical real-time paths. An extra layer of message processing is bad for latency. Such messages may need to bypass the Middleware.
Relations #
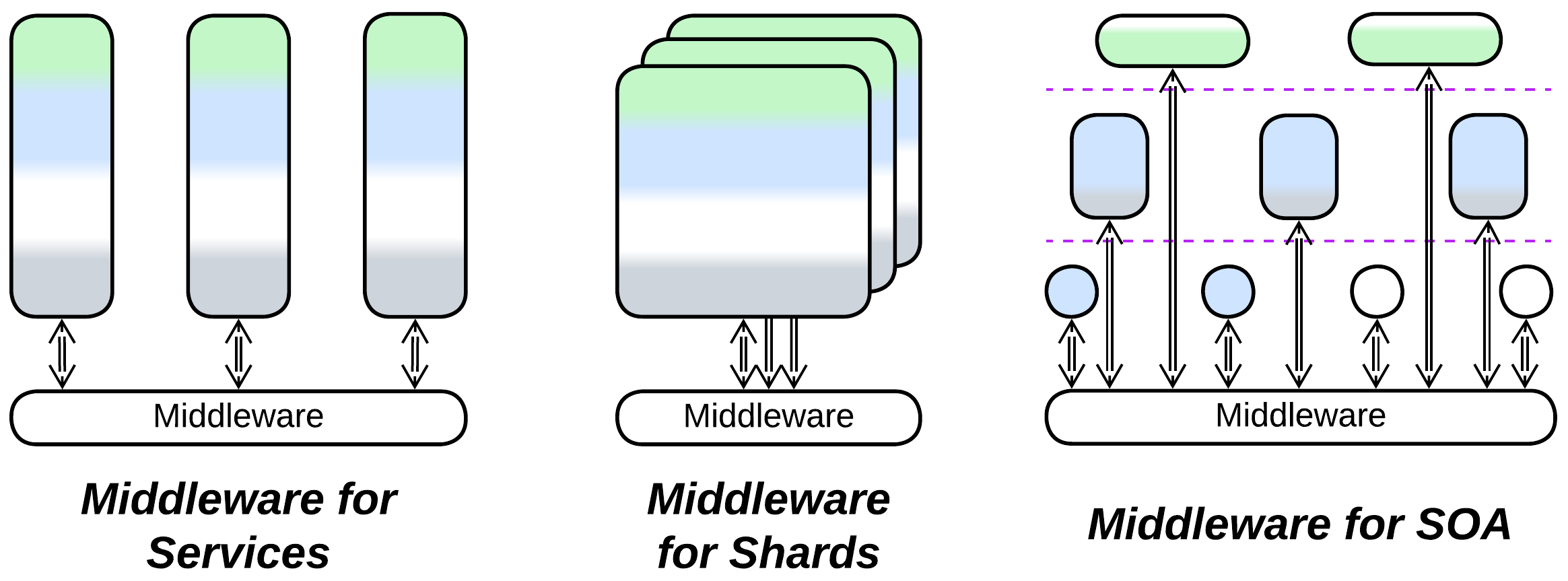
Middleware:
- Extends Services, Service-Oriented Architecture, or in rare cases, Shards or Layers.
- Can make a Bus of Buses (Hierarchy) or be merged with other extension metapatterns into several kinds of Combined Components.
- Is closely related to Shared Repository. A persistent Middleware employs a Shared Repository.
- Is usually implemented by a Mesh or Microkernel (which is often based on a Mesh).
Variants by functionality #
There are several dimensions of freedom with a Middleware, some of them may be configurable:
By addressing (channels, actors, pub/sub, gossip) #
Systems vary in the way their components address each other:
- Channels (one to one) – components which need to communicate establish a message channel between them. Once created, the channel accepts messages or a data stream on its input end and transparently delivers them to its output end. Examples: sockets, Unix pipes, and private chats.
- Actors (many to one) – each component has a public mailbox. Any other component that knows its address or name may push a message into it. Examples: e-mail.
- Publish/subscribe (one to many) – a component can publish events to topics. Other components subscribe to those topics and one or all of the subscribers receive copies of a published event. Examples: IP multicast and subscriptions for e-mail notifications.
- Gossip (many to many) – an instance of a component periodically synchronizes its version of the system’s state with random other instances, which further spread the updates. As time passes, more and more participants become aware of the changes in the system, leading to eventual consistency of the replicas of the system’s state.
By flow (notifications, request/confirm, RPC) #
Control flow may take one or more of the following approaches:
- Notifications – a component sends a message about an event that occurred and does not really care about the further consequences or wait for a response.
- Request/confirm – a component sends a message which requests that another component does something and sends back the result. The sender may execute other tasks meanwhile. A request usually includes a unique id that will be added to the confirmation for the Middleware to know which of the requests in progress the confirmation belongs to.
- Remote procedure call (RPC) is usually built on top of a request/confirm protocol. The difference is that the sender blocks on the Middleware while waiting for the confirmation, thus to the application code the whole process of sending the request and waiting for the confirmation looks like a single method call.
By delivery guarantee #
If the transport (network) or the destination fails, a message may not be processed, or may be processed twice because of retries. A Middleware may promise to deliver messages:
- Exactly once. This is the slowest case which is implemented through distributed transactions. If the network, Middleware, or the message handler fails, there is no side effect, and the whole process of delivering and executing the message is repeated. The exactly once contract is used for financial systems where money should never disappear or duplicate during a transfer.
- At least once. On failure the message is redelivered, but the previous message could have already been processed (if only the confirmation was lost), thus there is a chance for a message to be processed twice. If the message is idempotent [MP], meaning that it sets a value (x = 42) instead of incrementing or decrementing it (x = x + 2), then we can more or less safely process it multiple times (x = 42; x = 42; x = 42;) and use the relatively fast exactly once guarantee.
- At most once. If anything fails, the message is lost and never retried. This is the fastest of the three guarantees, suitable for such monitoring applications as weather sensors – it is not too bad if a single temperature measurement disappears when you receive hundreds of them every day.
- At will (no guarantee). As with the bare UDP transport, a message may disappear, become duplicated, or arrive out of order. That fits real-time streaming protocols (video or audio calls) where it is acceptable to skip a frame while a frame coming too late is of no use at all. Each frame contains its sequence number, and it is up to the application to reorder and deduplicate the frames it receives.
By persistence #
A Middleware with a delivery guarantee needs to store messages whose delivery has not yet been confirmed. They may be:
- Written to a database of the broker.
- Persisted in a distributed database in brokerless (Mesh) systems.
- Replicated over an in-memory Mesh storage (like Data Grid).
If the messages are stored indefinitely, the Middleware becomes a Persistent Event Log or even a Shared Event Store with the schemas of the stored events coupling the involved services [DEDS] just like the database schema does in Shared Repository.
By structure (Microkernel, Mesh, Broker) #
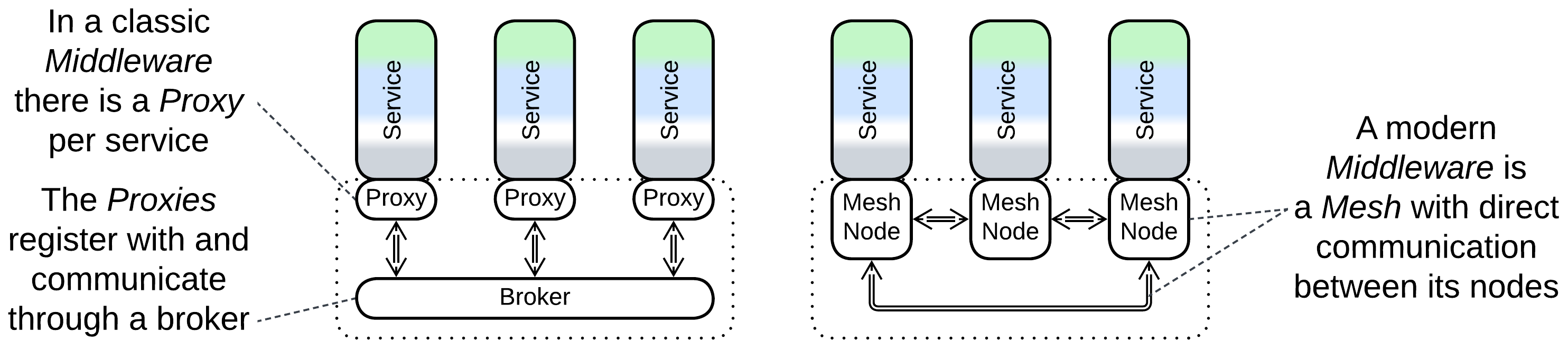
A Middleware may be:
- Implemented by an underlying operating or virtualization system (see Microkernel).
- Run as a Mesh of identical modules co-deployed with the distributed components as Sidecars.
- Rely on a single broker [POSA1, POSA4, EIP] for coordination.
The last configuration is simpler but features a single point of failure unless multiple instances of the broker are deployed and kept synchronized.
Examples of merging Middleware and other metapatterns #
There are several patterns which extend Middleware with other functions:
Message Bus #

A Message Bus [EIP] employs one or more Adapters per service to let the services intercommunicate even if they differ in protocols. That helps to integrate legacy services without much change to their code but it degrades overall performance as up to two protocol translations per message are involved.
Service Mesh #
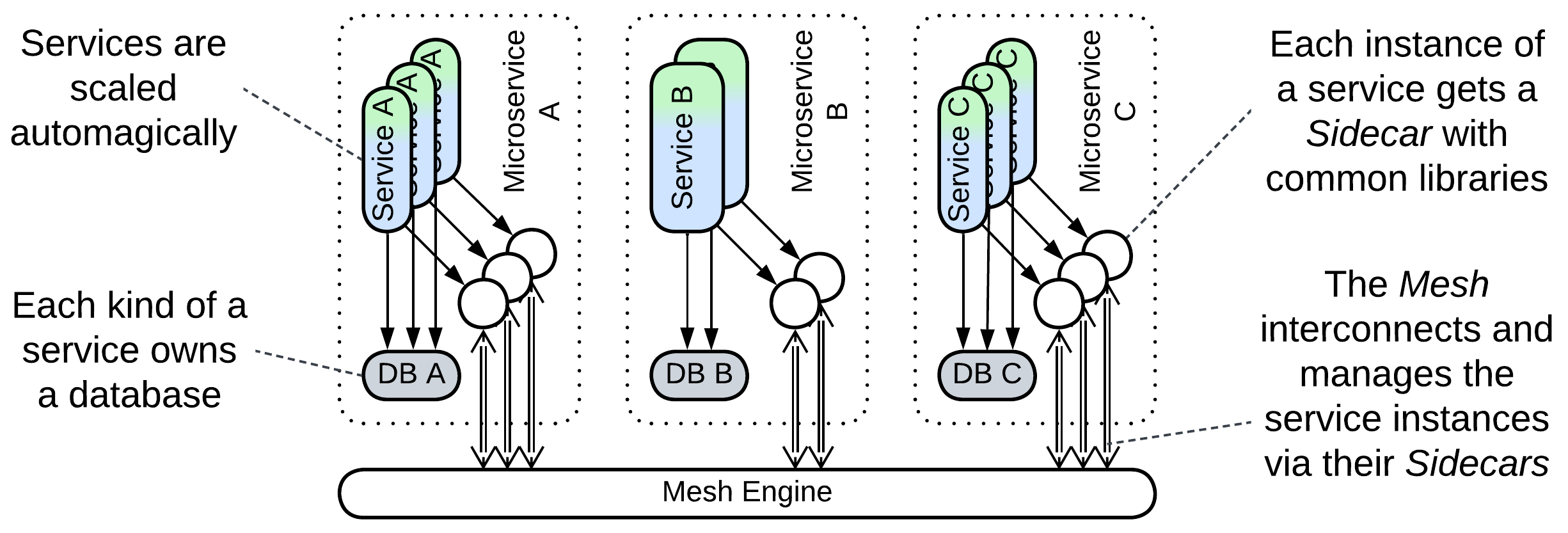
Service Mesh [FSA, MP] is a smart Mesh-based Middleware that manages service instances and employs at least one co-located Proxy (called Sidecar [DDS]) per service instance deployed. The Sidecars may provide protocol translation and cover cross-cutting concerns such as encryption or logging. They make a good place for shared libraries.
The internals of Service Mesh are discussed in the Mesh chapter.
Event Mediator #

Event Mediator [FSA], which pervades both Event-Driven Architectures and Nanoservices, melds a Middleware (used for delivery of messages) and an Orchestrator (that coordinates high-level use cases). A message arrives to a service and is responded to without any explicit component on the service’s side – it appears out of thin Middleware which implements the entire integration logic.
Slightly more details on the Event Mediator are provided in the Orchestrator chapter.
Persistent Event Log, Shared Event Store #

When a Middleware persists messages, it takes on the function (and drawbacks) of a Shared Repository. A Persistent Event Log allows to replay incoming events for a given service (to help a debug session or fix data corrupted by a bug) while a Shared Event Store also captures changes of the internal states of the services [DEDS], replacing their private databases. However, with either approach, changing an event field impacts all the services that use the event and may involve rewriting the entire event log (system’s history) [DEDS].
This pattern is detailed in the Combined Component chapter.
Enterprise Service Bus (ESB) #

Enterprise Service Bus (ESB) [FSA] is a mixture of Message Bus and Event Mediator. A ESB blends a Middleware and an Orchestrator and adds an Adapter per service as a topping. It emerged to connect components that originated in incompatible networks of organizations that had been acquired by a corporation.
See the chapter about Service-Oriented Architecture.
Evolutions #
A Middleware is unlikely to be removed (though it may be replaced) once it is built into a system. There are few evolutions for Middleware because it is usually a third-party product and thus unlikely to be modified in-house:
- If the Middleware in use does not fit the preferred mode of communication between some of your services, there is the option to deploy a second, specialized Middleware.
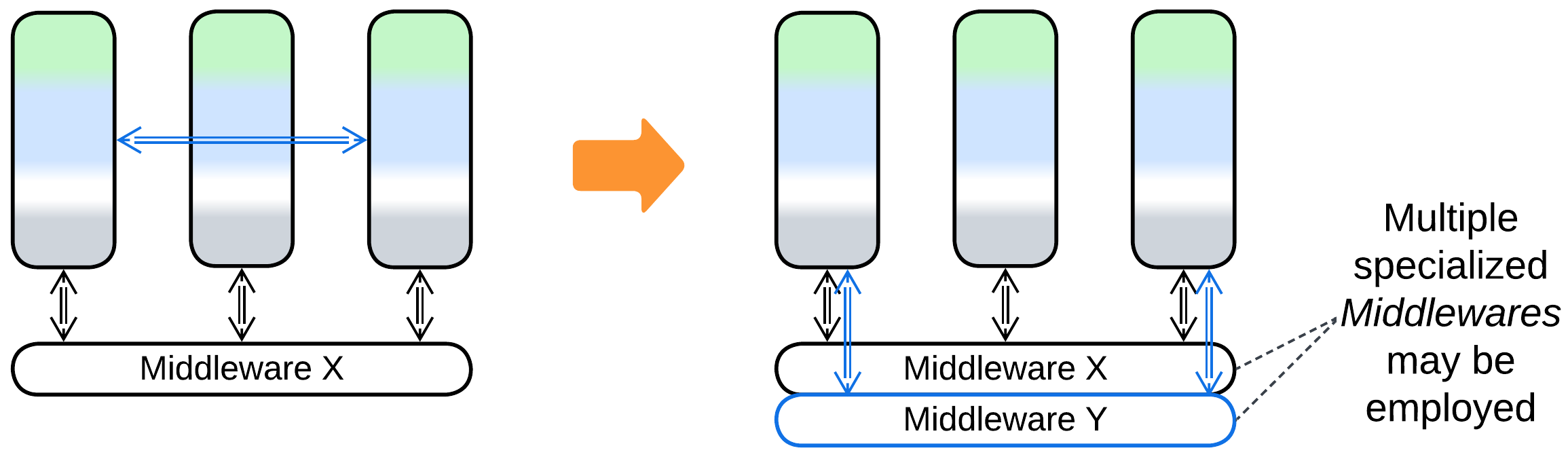
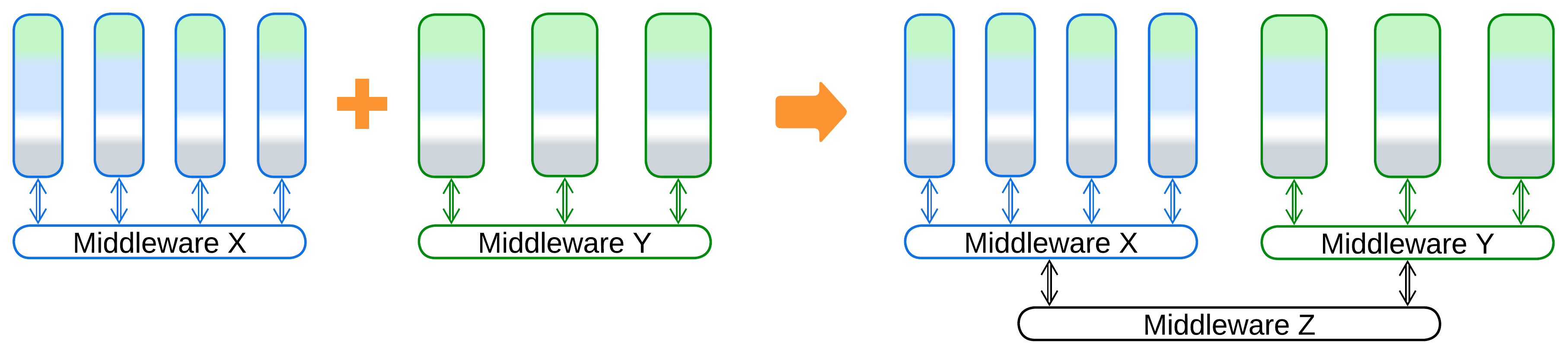
- If several existing systems need to be merged, that is accomplished by adding yet another layer of Middleware, resulting in a Bottom-up Hierarchy (Bus of Buses).
Summary #
A Middleware is a ready-to-use component that provides a system of services with means of communication, scalability, and error recovery. It is very common in distributed backends.