Shards #
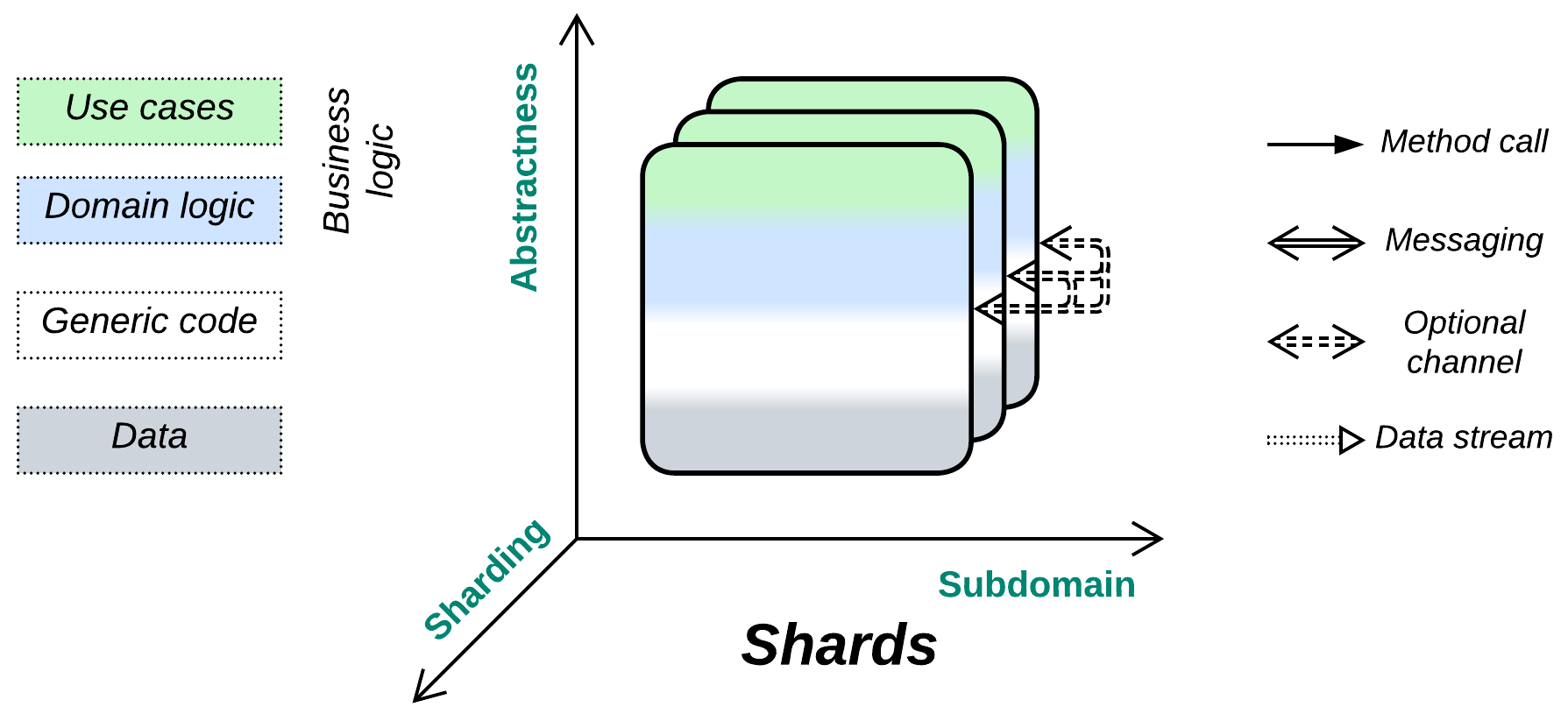
Attack of the clones. Solve scalability in the most straightforward manner.
Known as: Shards, Instances, Replicas [DDS].
Variants:
By isolation:
- Multithreading,
- Multiple processes,
- Distributed instances.
By state:
- Persistent slice: Sharding / Shards [DDS] / Partitions [DDIA] / Cells (Amazon definition),
- Persistent copy: Replica [DDS],
- Stateless: Pool [POSA3] / Instances / Replicated Stateless Services [DDS] / Work Queue [DDS],
- Temporary state: Create on Demand.
Structure: A set of functionally identical subsystems with little or no intercommunication.
Type: Implementation.
| Benefits | Drawbacks |
|---|---|
| Good scalability | It’s hard to synchronize the system’s state |
| Good performance |
References: [POSA3] is dedicated to pooling and resource management; [DDS] reviews Shards, Replicas and Stateless Instances; [DDIA] covers sharding and synchronization of Replicas in depth; Amazon promotes full-system sharding as Cell-Based Architecture.
Shards are multiple and, in most cases, independent instances of a component or subsystem which the pattern is applied to. They provide scalability, often redundancy and sometimes locality, at the cost of slicing or duplicating the component’s state (writable data), which obviously does not affect inherently stateless components. Most of this pattern’s specific evolutions look for a way to coordinate shards at the logic or data level.
There is a sibling metapattern, Mesh, in which instances of a component closely communicate among themselves. The difference between the patterns lies in the strength of interactions: while each shard exists primarily to serve its clients, a Mesh node’s priority is preserving the Mesh itself from falling prey to entropy, making the Mesh into a reliable distributed (virtual) layer. Some systems, such as distributed databases, hold the middle ground – their shards or nodes both intercommunicate intensely and execute a variety of client requests.
Performance #
A shard retains the performance of the original subsystem (a Monolith in the simplest case) as long as it runs independently. Any task that involves intershard communication has its performance degraded by data serialization and network latency. And as soon as multiple shards need to synchronize their states you find yourself on the horns of a dilemma: damage data consistency through write conflicts or kill performance with distributed transactions [FSA].
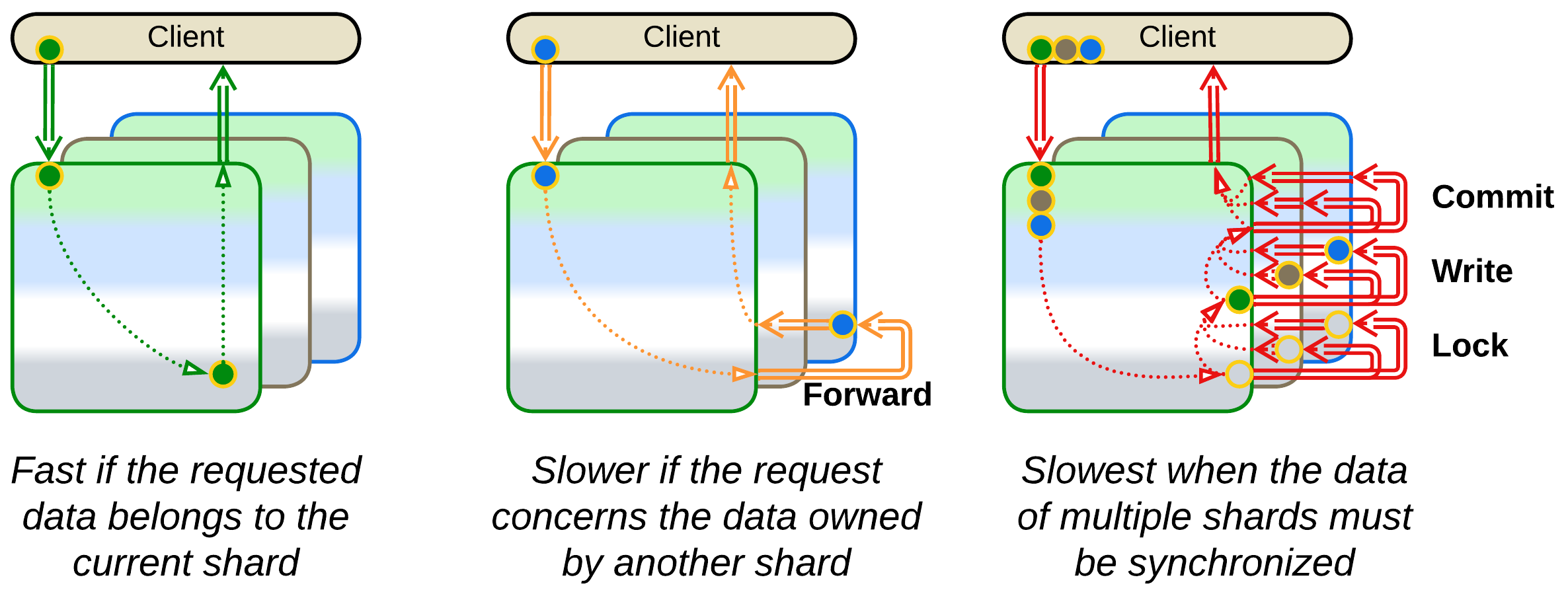
A Shared Repository (or its derivation, the Space-Based Architecture) is a common solution to let multiple shards access the same dataset. However, it does not solve the performance vs consistency conflict (which is rooted in the CAP theorem) but only encapsulates its complexity inside a ready-made third-party component, making your life easier.
Dependencies #
You may need to make sure that all the shards are instances of the same version of your software or at least that their interfaces and contracts are backward- and forward-compatible.
Applicability #
A sharded system features properties of a pattern it replicates (a single-component Monolith, local layered application or distributed Services). Its peculiarities that originate with the Shards’ scalability, are listed below.
Shards are good for:
- High or variable load. You need to scale your service up (and sometimes down). With Shards you are not limited to a single server’s CPU and memory.
- Survival of hardware failures. A bad HDD or failing RAM does not affect your business if there is another running instance of your application. Still, make sure that your Load Balancer and Internet connection are replicated as well.
- Improving worst case latency. If your service suffers from latency spikes, you can run a few replicas of it in parallel, broadcasting every user request to all of them, and returning the fastest response. Adding a single replica turns your p90 into p99.
- Improving locality. A world-wide business optimizes latency and costs by deploying an instance of its software to a local data center in every region of interest (or even to its clients’ browsers)!
- Canary Release. It is possible to deploy an instance of your application featuring new code along with the old, stable instances. That tests the update in production.
Shards’ weak point is:
- Shared data. If multiple instances of your application need to modify the same dataset, that means that none of them properly owns the data, thus you have to rely on an external component (a data layer, implying Layers and Space-Based Architecture or another kind of Shared Repository).
Relations #
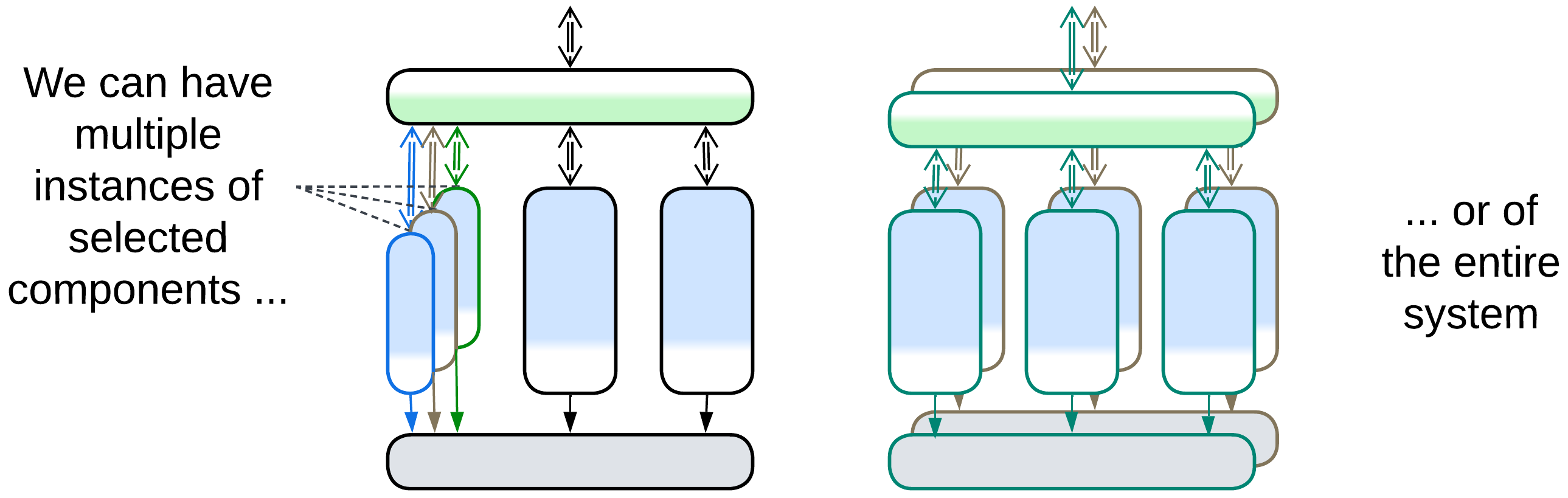
Shards:
- Applies to a Monolith or any kind of subsystem.
- Can be extended with Middleware, Shared Repository, Proxies or Orchestrator.
- Is the foundation for Mesh.
Variants by isolation #
There are intermediate steps between a single-threaded component and distributed Shards which gradually augment the pros and cons of having multiple instances of a subsystem:
Multithreading #
The first and very common advance towards scaling a component is running multiple execution threads. That attempts to utilize all the available CPU cores or memory bandwidth but requires protecting the data from simultaneous access by several threads, which in turn may cause deadlocks.
| Benefits | Drawbacks |
|---|---|
| Limited scalability | More complex data access |
Multiple processes #
The next stage is running several (usually single-threaded) instances of the component on the same system. If one of them crashes, others survive. However, sharing data among them and debugging multi-instance scenarios becomes non-trivial.
| Benefits | Drawbacks |
|---|---|
| Limited scalability | Non-trivial shared data access |
| Software fault isolation | Troublesome multi-instance debugging |
Distributed instances #
Finally, instances of the subsystem may be distributed over a network to achieve nearly unlimited scalability and fault tolerance by sacrificing the consistency of the whole system’s state.
| Benefits | Drawbacks |
|---|---|
| Full scalability | No shared data access |
| Full fault isolation | Hard multi-instance debugging |
| No good way to synchronize state of the instances |
Variants by state #
Sharding can often be transparently applied to individual components of data processing systems. That does not hold for control systems which need centralized decisions based on the modeled system’s state, which must be accessible as a whole, thus the main business logic that owns the model (last known state of the system) cannot be sharded.
Many kinds of Shards require an external coordinating module (Load Balancer) to assign tasks to the individual instances. In some cases the coordinator may be implicit, e.g. an OS socket or scheduler. In others it may be replicated and co-located with each client (as an Ambassador [DDS]).
Shards usually don’t communicate with each other directly. The common exception is Mesh which includes distributed databases and actor systems that explicitly rely on communication between the instances.
There are several subtypes of sharding that differ in the way they handle state:
Persistent slice: Sharding, Shards, Partitions, Cells (Amazon definition) #
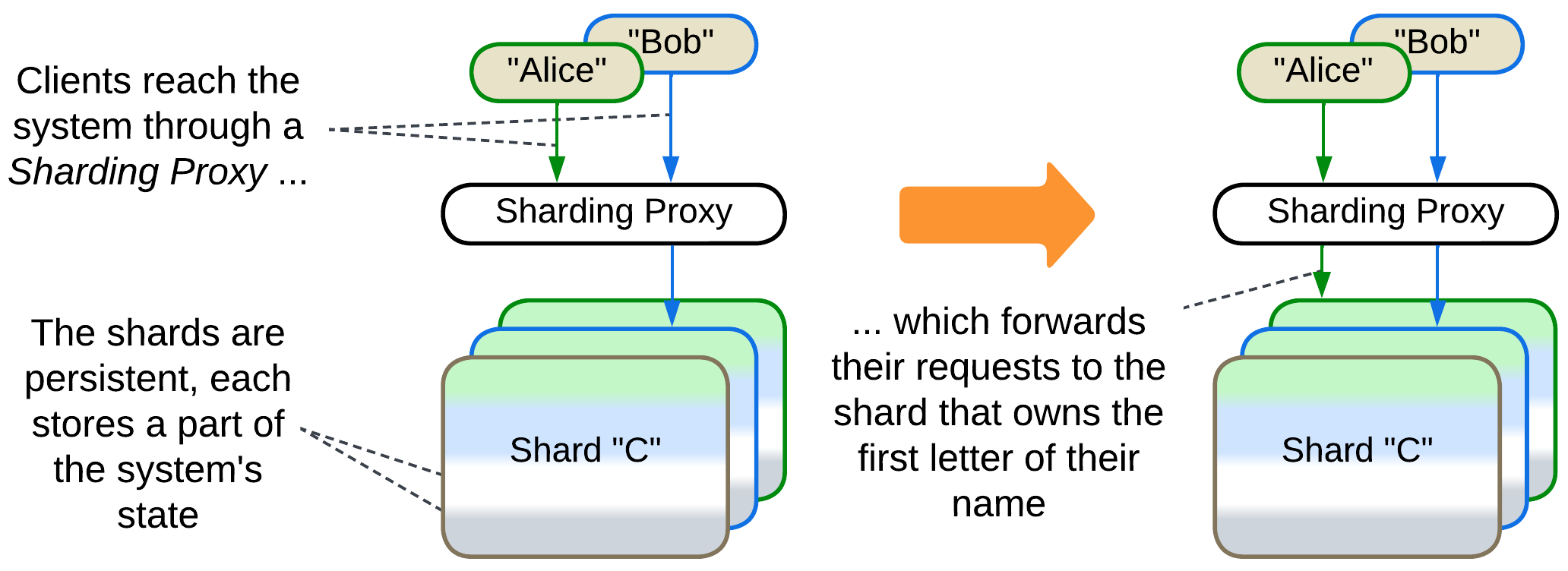
Shards [DDS] own the non-overlapping parts of the system’s state. For example, a sharded phonebook (or DNS) would use one shard for all contacts with initial “A”, another shard for contacts with initial “B” and so on (in reality they use hashes [DDIA]). A large wiki or forum may run several servers, each storing a subset of the articles. This is proper sharding, which is also called partitioning [DDIA] in the world of databases.
Names are not evenly distributed among letters. Many names start with A but few start with Q. If we use the first letter of a user’s name to assign them to a shard, the shard that serves users whose names start with A will be much more loaded than the one responsible for the letter Q. Therefore, real-world systems rely on hashing [DDIA] – calculation of a checksum of the user’s name which yields a seemingly random number. Then we divide the checksum by the total number of shards we have and use the remainder as the id of the shard that has the user’s data. For example, CRC16(“Bender”) = 52722. If we have 10 shards, Bender goes to (52722 % 10 = 2) the 3rd one.
Cells, according to the Amazon terminology, are copies of a whole system deployed to several data centers, each serving local users. The locality improves latency and saves on Internet traffic while having multiple instances of the system up and running provides availability. The downside of this approach is its complexity and amount of global traffic needed to keep the Cells in sync.
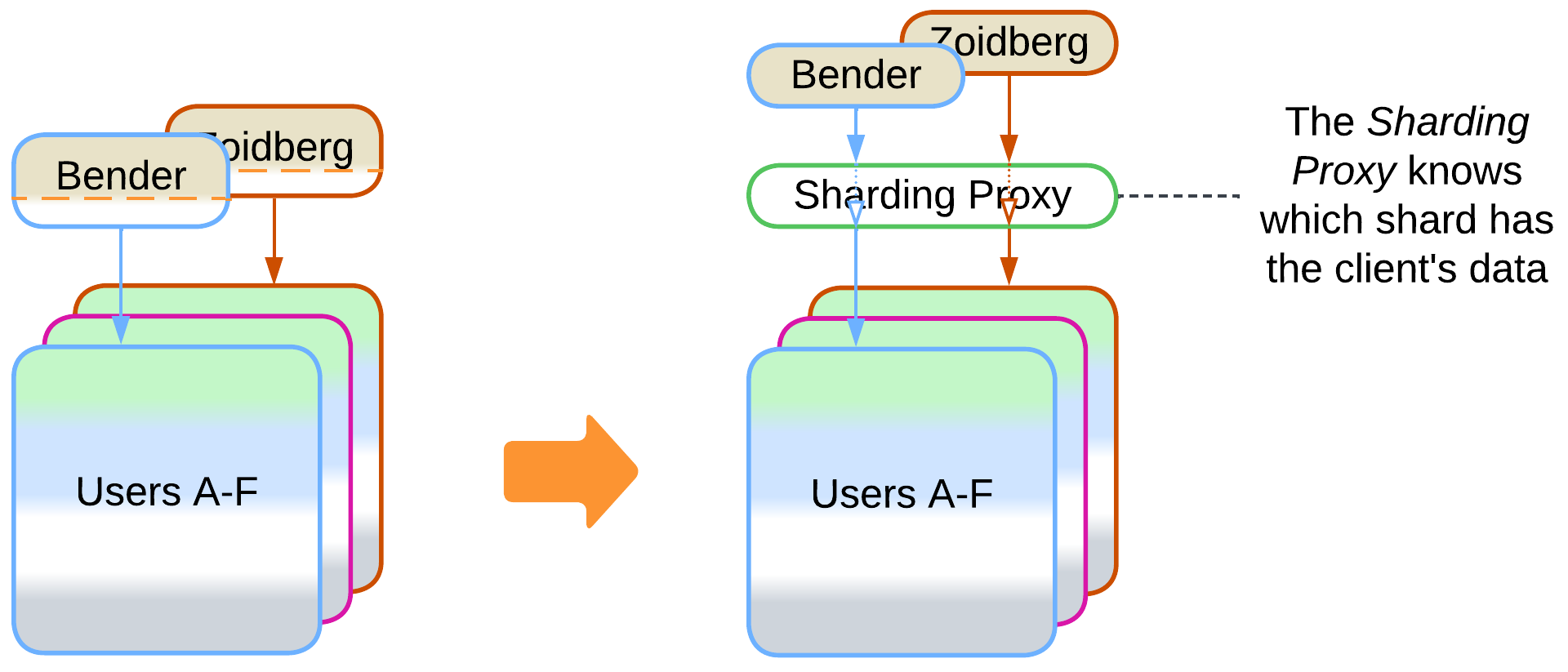
It usually takes a stand-alone Sharding Proxy [DDS] – a kind of Load Balancer – to route client’s requests to the shard that owns its data. However, there are other options [DDIA]:
- The Sharding Proxy may be deployed as a client-side Ambassador [DDS] to avoid the extra network hop. This approach requires a means for keeping the Ambassadors up-to-date with your system’s code.
- You can publish your sharding function [DDS] and the number of shards in your public API to let your clients choose which shard to access without your help. That may work for internal clients implemented by your or neighbor team.
- Finally, each shard may be able to forward client requests to any other shard – making each shard into a Sharding Proxy and an entry point into the resulting Mesh. If your client accesses a wrong shard, the request is still served, though a little slower, through being forwarded between the shards [DDIA].
Sharding solves scaling of an application both in regard to the number of its clients and to the size of its data. However, it works well only if each client’s data is independent from other clients. Moreover, if one of the shards crashes, the information it owns becomes unavailable unless replication (see below) has been set up as well.
Persistent copy: Replica #
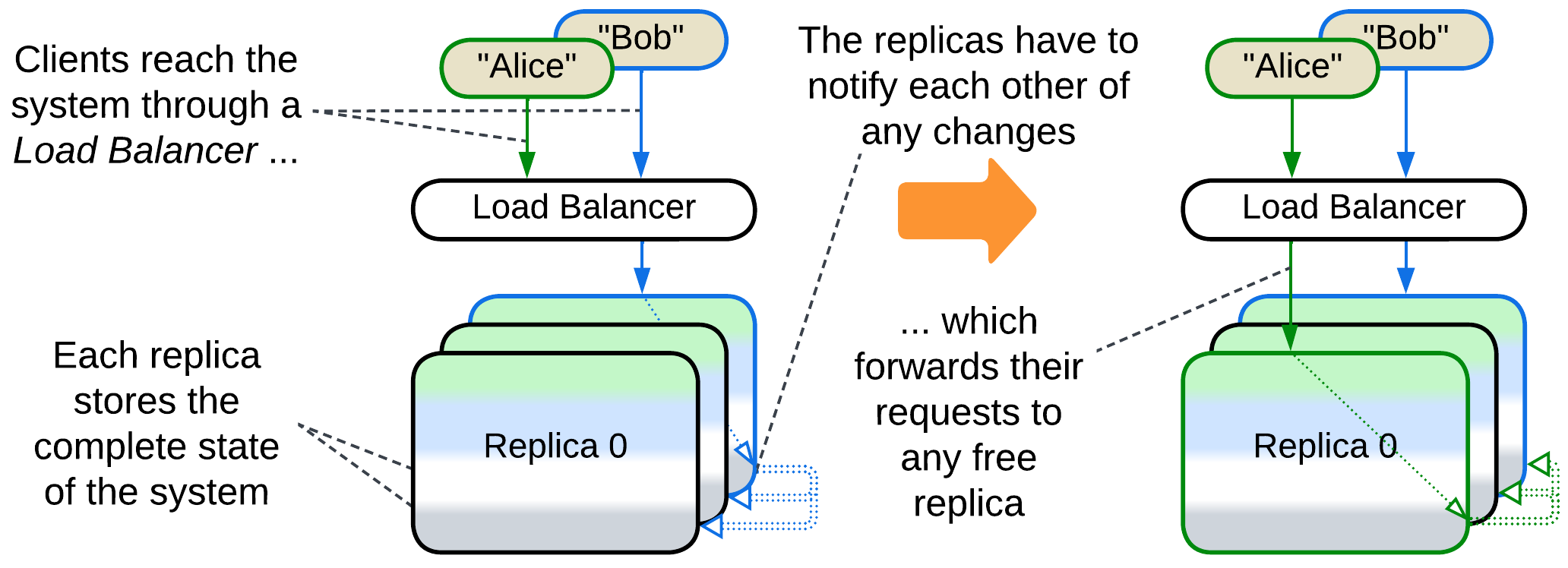
Replicas [DDS] are identical copies of a stateful (sub)system. Replication improves the system’s throughput (as each replica serves client requests) and its stability (as a fault in one replica does not affect others which may quickly take up the failed replica’s clients). Replicas may also be used to improve tail latency through Request Hedging: each request is sent to several replicas in parallel and you use the first response which you receive. Mission-critical hardware runs three copies and relies on majority voting for computation results.
The hard part comes from the need to keep the replicas’ data in sync. The ordinary way is to let the replicas talk to each other on each data update. If the communication is synchronous that may greatly slow down the processing of requests, while if it is asynchronous the system suffers data conflicts when multiple clients change the same value simultaneously. Synchronization code is quite complex, thus you will likely use a ready-made Space-Based Architecture framework instead of writing one of your own.
Another option found in the field is keeping the replicas only loosely identical. That happens when isolated cache servers make a Caching Layer [DDS]. As clients tend to send similar requests, the data inside cache is more or less the same by the law or large numbers.
And if your traffic is read-heavy, you may turn to Polyglot Persistence by segregating your replicas into the roles of a fully-functional leader [DDIA] and derived, read-only followers. The followers serve only the read requests while the leader processes the write requests which make it update its data and broadcast the changes to all its followers. And if the leader dies, one of its followers is elected to become a new leader. As a refinement of this idea, the code of the service itself may be separated into write (command) and read (query) services (Command Query Responsibility Segregation aka CQRS).
Finally, you can mix sharding and replication to make sure that the data of each shard is replicated, either in whole among identical components [DDS] or piecemeal all over the system [DDIA]. That achieves fault tolerance for volumes of data too large to store unsharded.
Stateless: Pool, Instances, Replicated Stateless Services, Work Queue #
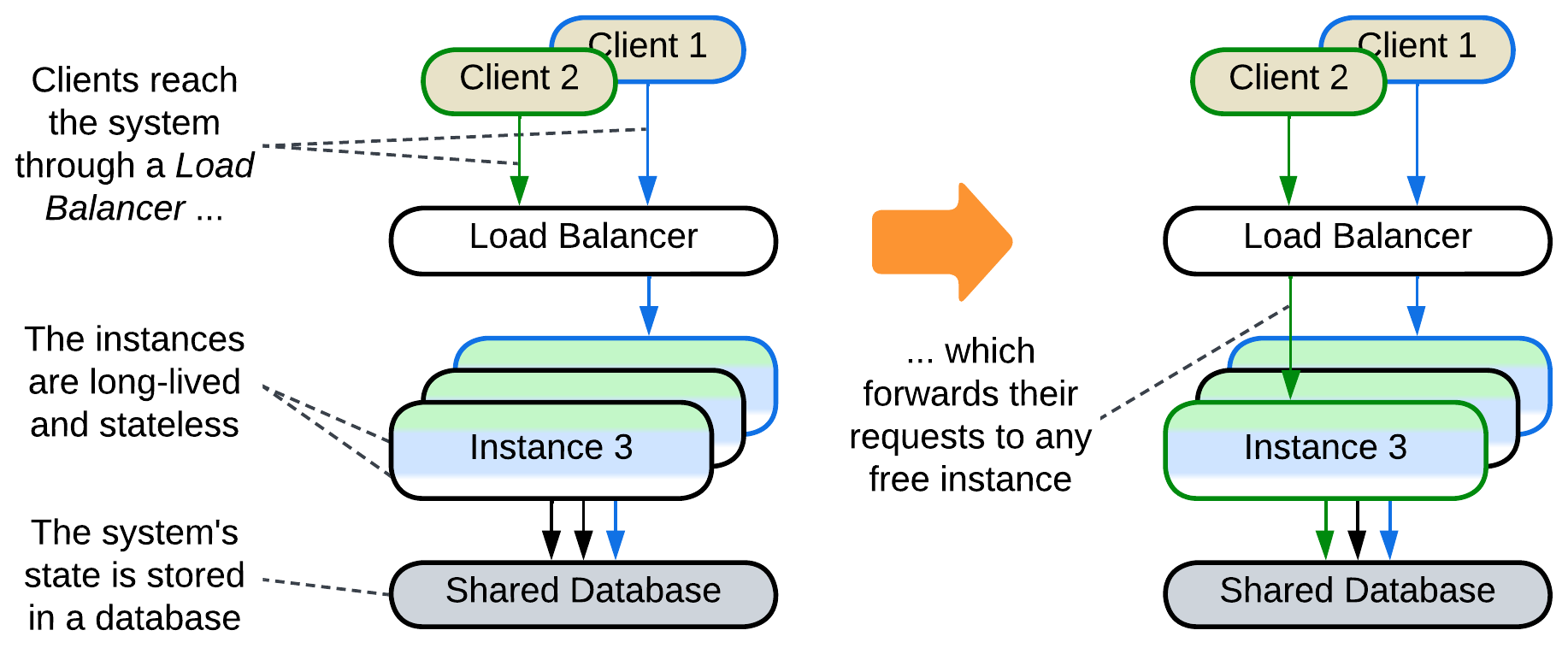
A predefined number (pool [POSA3]) of instances (workers) is created during the initialization of the system (Work Queue [DDS]). When the system receives a task, a Load Balancer assigns it to one of the idle instances from the pool. As soon as the instance finishes processing its task it returns to the pool. The instances don’t store any state while idle, thus they are also called Replicated Stateless Services [DDS]. A well-known example of this pattern is FastCGI.
This approach allows for rapid allocation of a worker to any incoming task, but it uses a lot of resources even when there are no requests to serve and the system may still be overwhelmed at peak load. Moreover, a Shared Database is usually involved for the sake of persistent storage, limiting the pattern’s scalability.
Many cloud services implement dynamic pools, the number of instances growing and shrinking according to the overall load: if all the current instances are busy serving user requests, new instances are created and added to the pool. If some of the instances are idle for a while, they are destroyed. Dynamic pooling is often implemented through Mesh, as in Microservices or Space-Based Architecture.
Temporary state: Create on Demand #
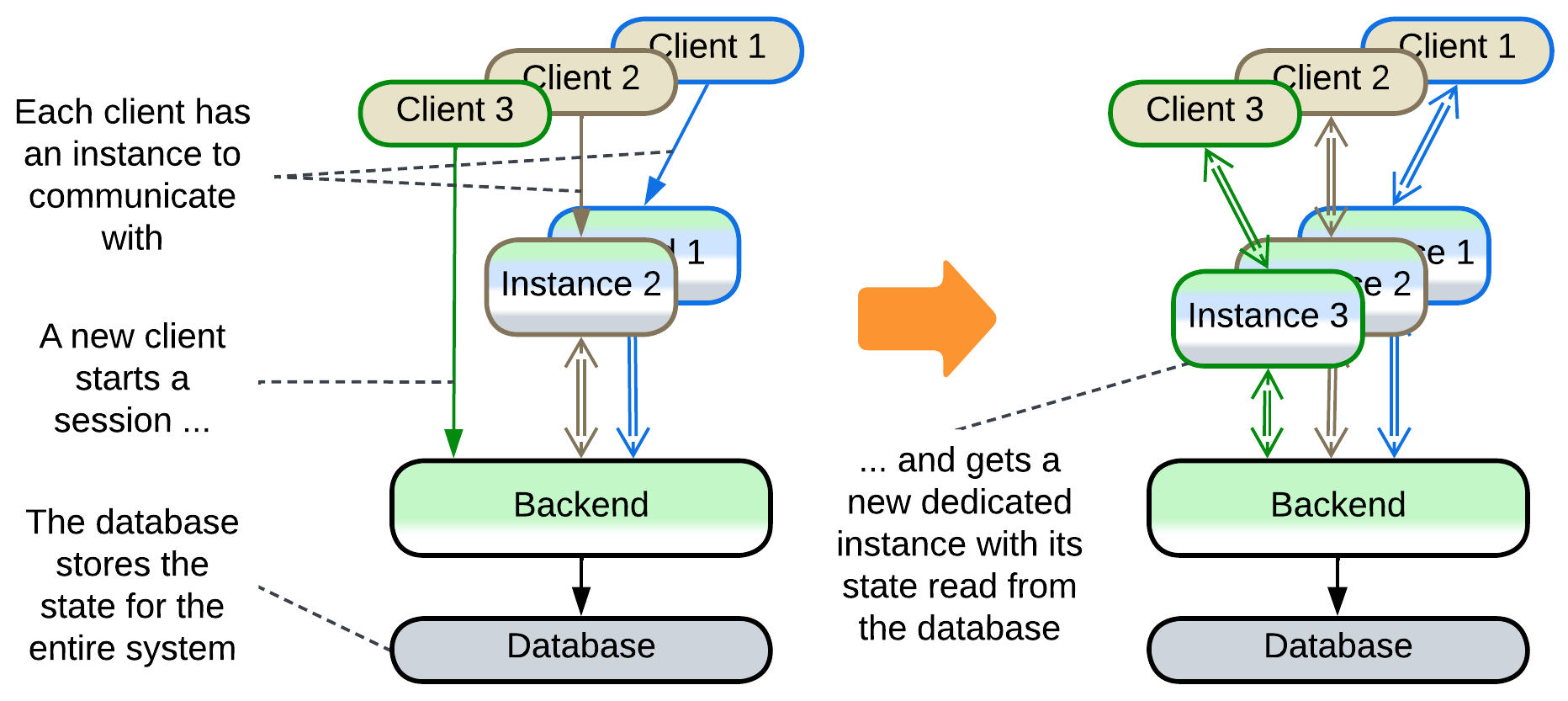
An instance is created for serving an incoming request and is destroyed when the request processing is finished. Upon creation it is initialized with all the client-related data to be able to interact with the client without much help from the backend. Examples include running web applications in clients’ browsers and client-dedicated actors in backends of instant messengers.
This approach provides perfect elasticity and flexibility of deployment at the cost of slower session establishment and it usually relies on an external shared layer for persistence: instances of a frontend are initialized from and send their updates to a backend which itself uses a database.
Evolutions #
There are two kinds of evolutions for Shards: those intrinsic to the component sharded and those specific to the Shards pattern. All of them are summarized below while Appendix E provides more details on the second kind.
Evolutions of a sharded monolith #
When Shards are applied to a single component, which is a Monolith, the resulting (sub)system follows most of the evolutions of Monolith:
- Layers allow for the parts of the system to differ in qualities (forces) and deployment. Various third-party components can be integrated and the code becomes better structured.
- Services or Pipeline help to distribute the work among multiple teams and may decrease the project’s complexity if the division yields loosely coupled components.
- Plugins and its subtypes, namely Hexagonal Architecture and Scripts, make the system more adaptable.
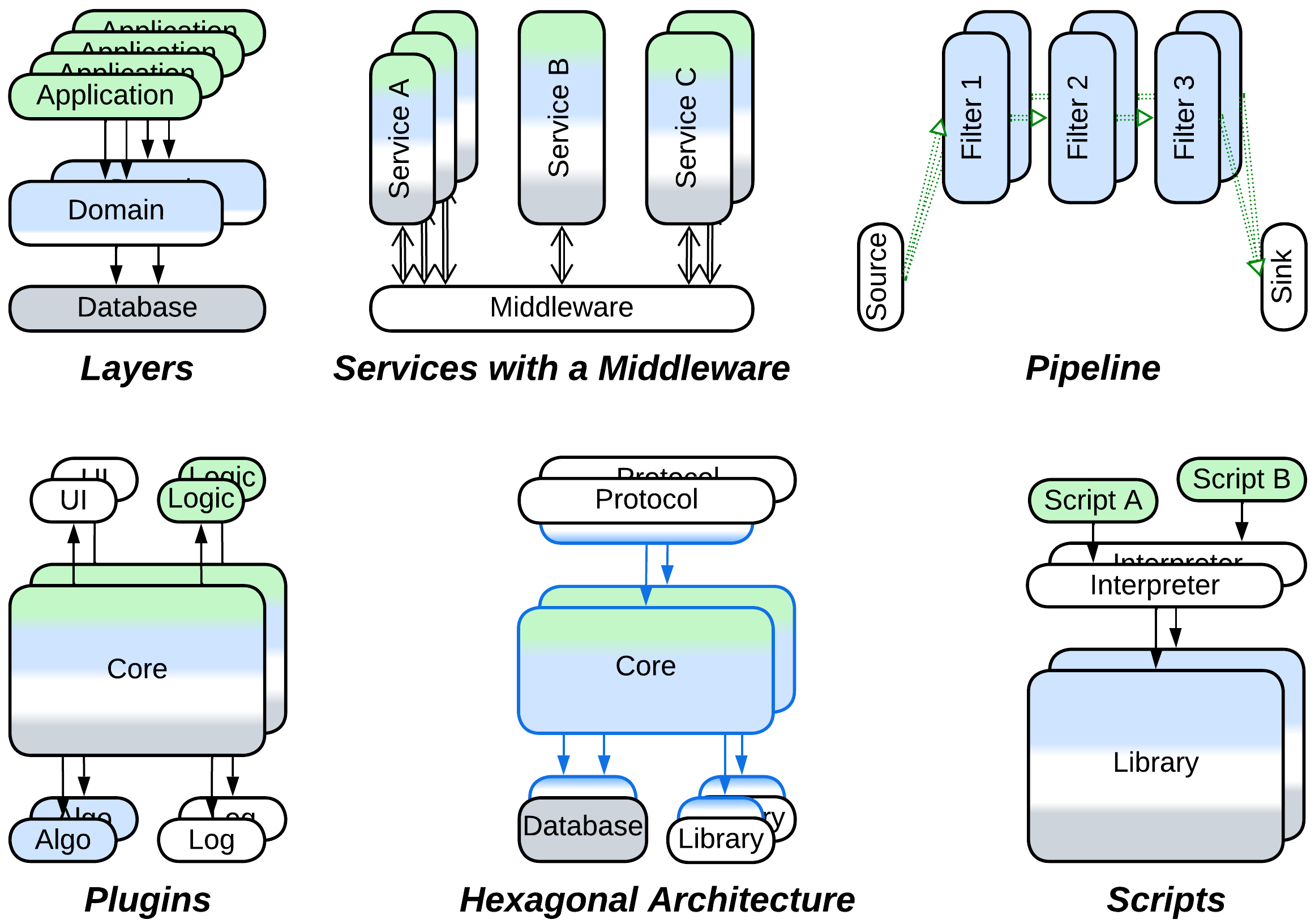
There is a benefit of such transformations which is important in the context of Shards: in many cases the resulting components can be scaled independently, arranging for a better resource utilization by the system (when compared to scaling a Monolith). However, scaling individual services usually requires a Load Balancer or Middleware to distribute requests over the scaled instances.
Evolutions that share data #
The issue peculiar to Shards is that of coordinating deployed instances, especially if their data becomes coupled. The most direct solution is to let the instances access the shared data:
- If the whole dataset needs to be shared, it can be split into a Shared Repository layer.
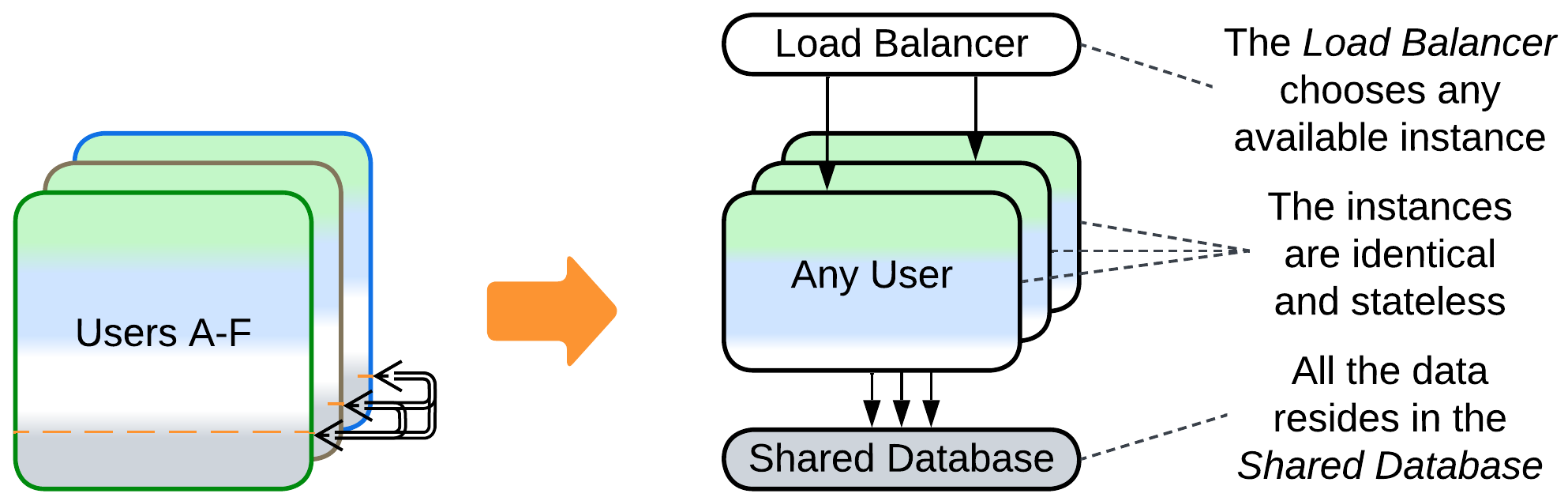
- If data collisions are tolerated, Space-Based Architecture promises low latency and dynamic scalability.
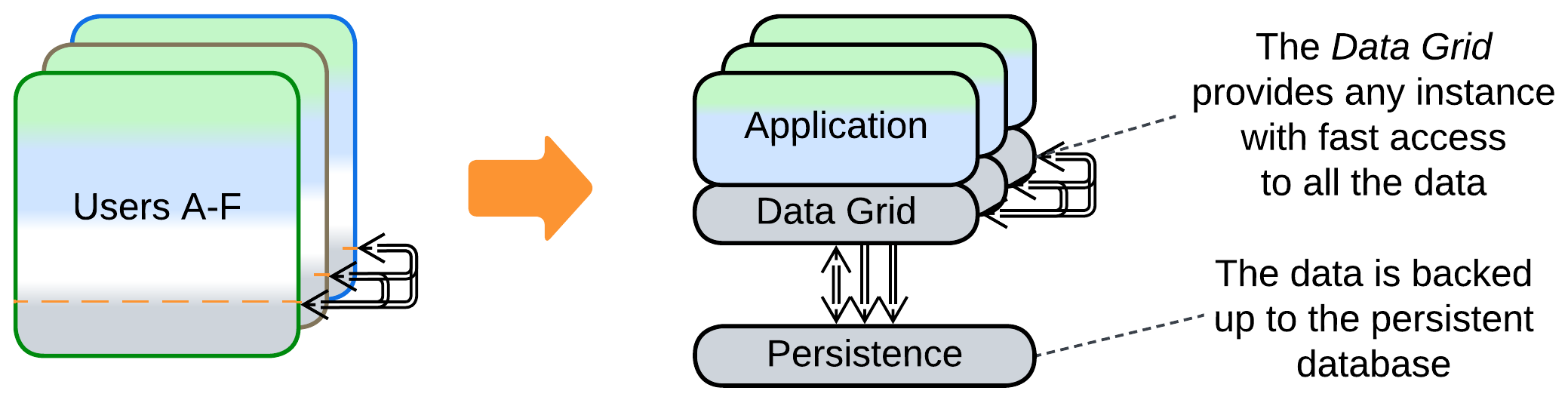
- If a part of the system’s data becomes coupled, only that part can be moved to a Shared Repository, making each instance manage two stores of data: private and shared.
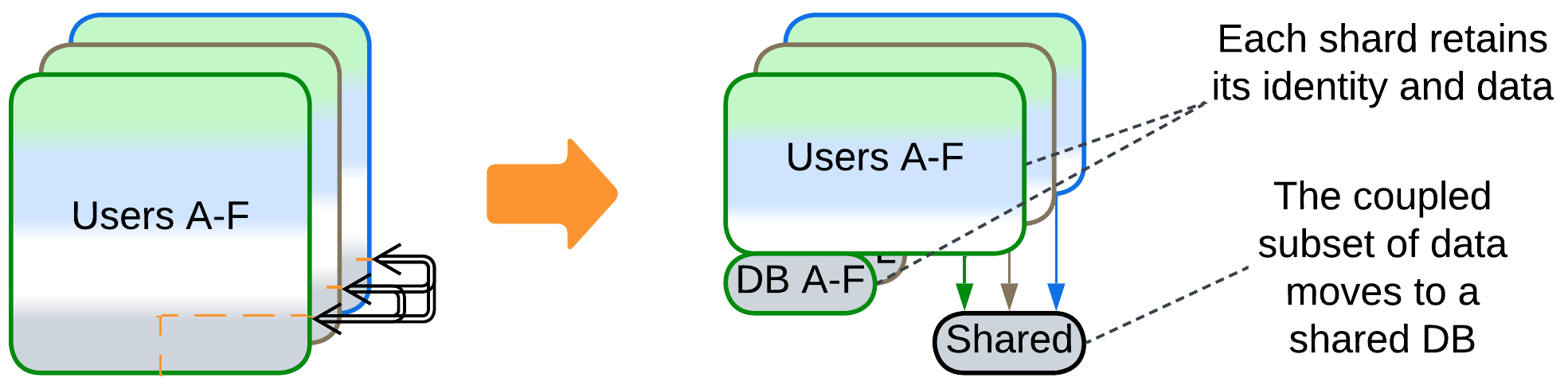
- Another possible option is to split a service that owns the coupled data and is always deployed as a single instance. The remaining parts of the system become coupled to that service, not to each other.
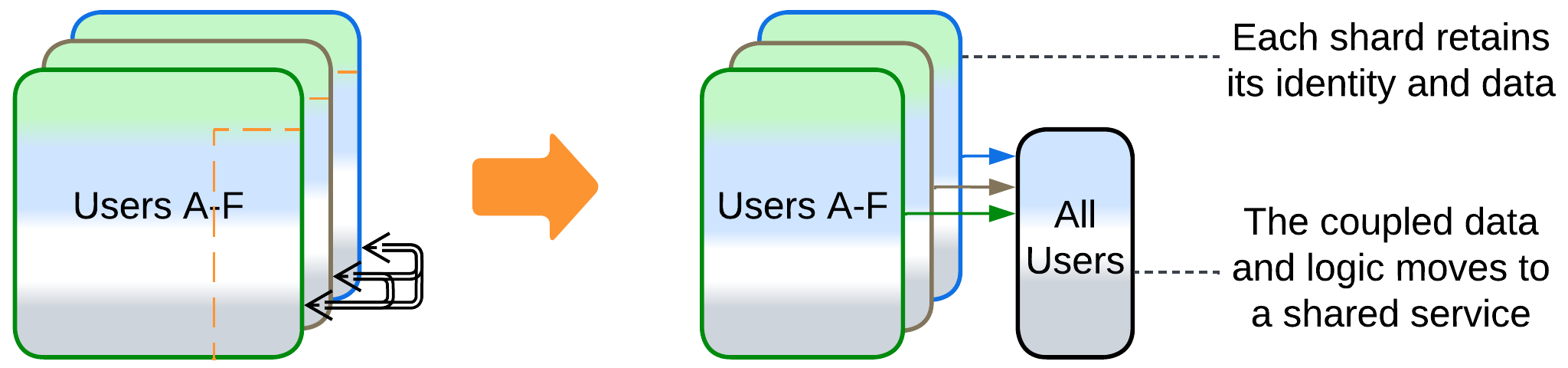
Evolutions that share logic #
Other cases are better solved by extracting the logic that manipulates multiple shards:
- Splitting a service (as discussed above) yields a component that represents both shared data and shared logic.
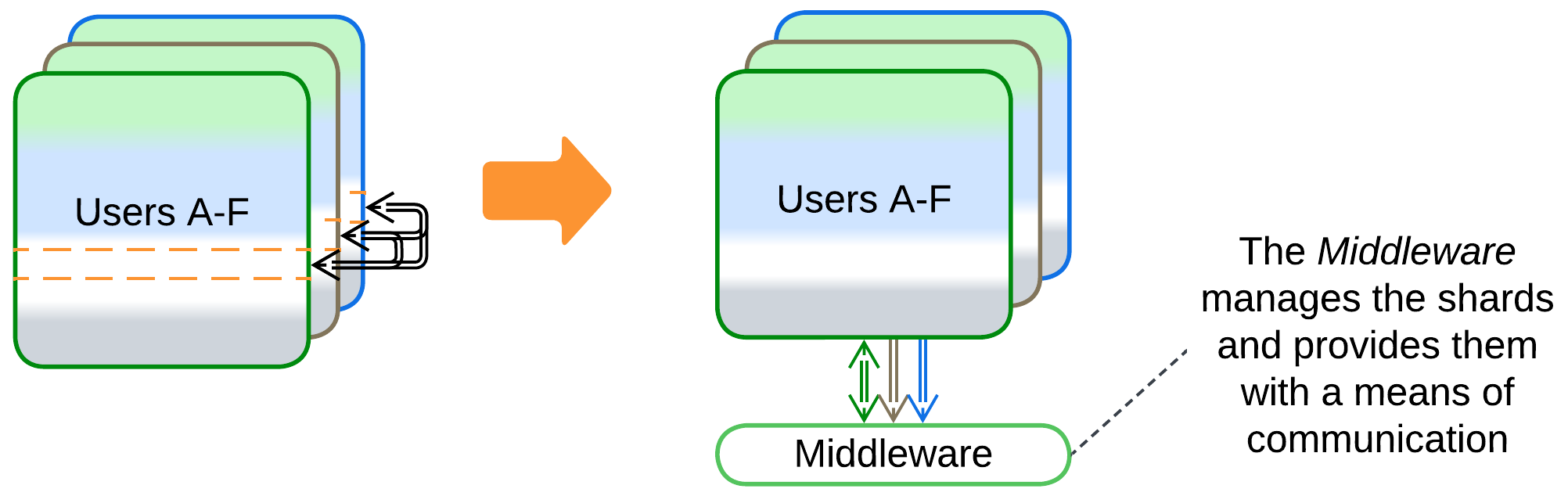
- Adding a Middleware lets the shards communicate with each other without maintaining direct connections. It also may do housekeeping: error recovery, replication, and scaling.
- A Sharding Proxy hides the shards from the system’s clients.
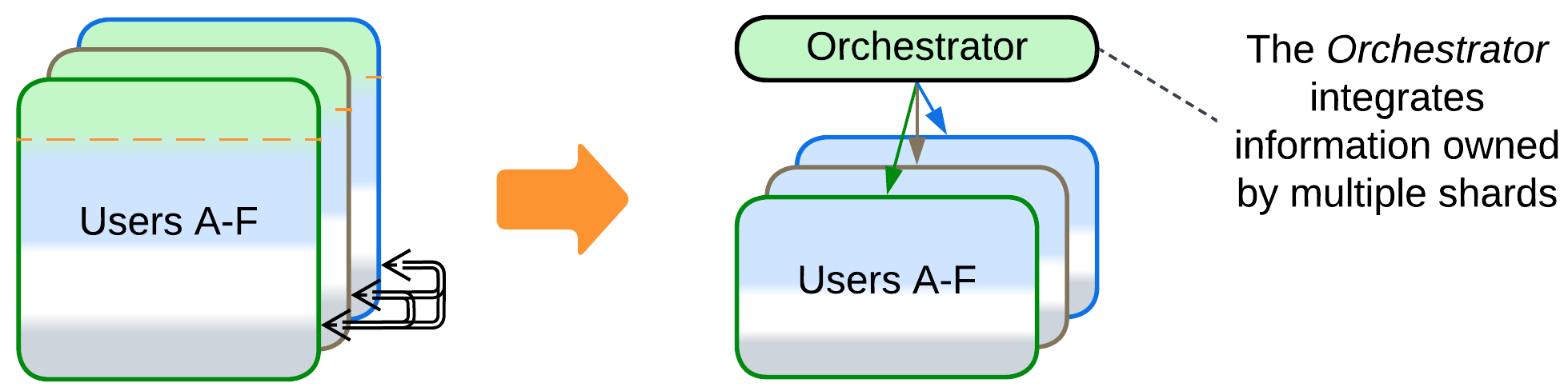
- An Orchestrator calls multiple shards to serve a user request. That relieves the shards of the need to coordinate their states and actions by themselves.
Summary #
Shards are multiple instances of a component or subsystem which is thus made scalable and more fault tolerant. Sharding does not change the nature of the component it applies to and it usually relies on a Load Balancer or Middleware to manage the instances it spawns. Its main weakness appears when the shards need to intercommunicate, often to the end of synchronizing their data.